C’est quoi le contexte ?
- Contexte d’intention: ce que tu veux obtenir du modèle. Par exemple, un system prompt sert généralement d’instructions de haut niveau sur la façon dont tu veux que le modèle se comporte. La plupart du « prompting » dans Cursor relève du contexte d’intention. « Passe ce bouton du bleu au vert » est un exemple d’intention explicite ; c’est prescriptif.
- Contexte d’état: l’état du monde à l’instant T. Fournir à Cursor des messages d’erreur, des logs de console, des images ou des extraits de code sont des exemples de contexte lié à l’état. C’est descriptif, pas prescriptif.
Fournir du contexte dans Cursor
- Des hallucinations où le modèle essaie de faire du pattern matching (alors qu’il n’y a pas de pattern), entraînant des résultats inattendus. Ça peut arriver souvent avec des modèles comme
claude-3.5-sonnetquand ils n’ont pas assez de contexte. - L’Agent qui cherche à réunir le contexte par lui-même en explorant la codebase, en lisant des fichiers et en appelant des outils. Un modèle avec de fortes capacités de raisonnement (comme
claude-3.7-sonnet) peut aller assez loin avec cette stratégie, et fournir le bon contexte initial va en déterminer la trajectoire.
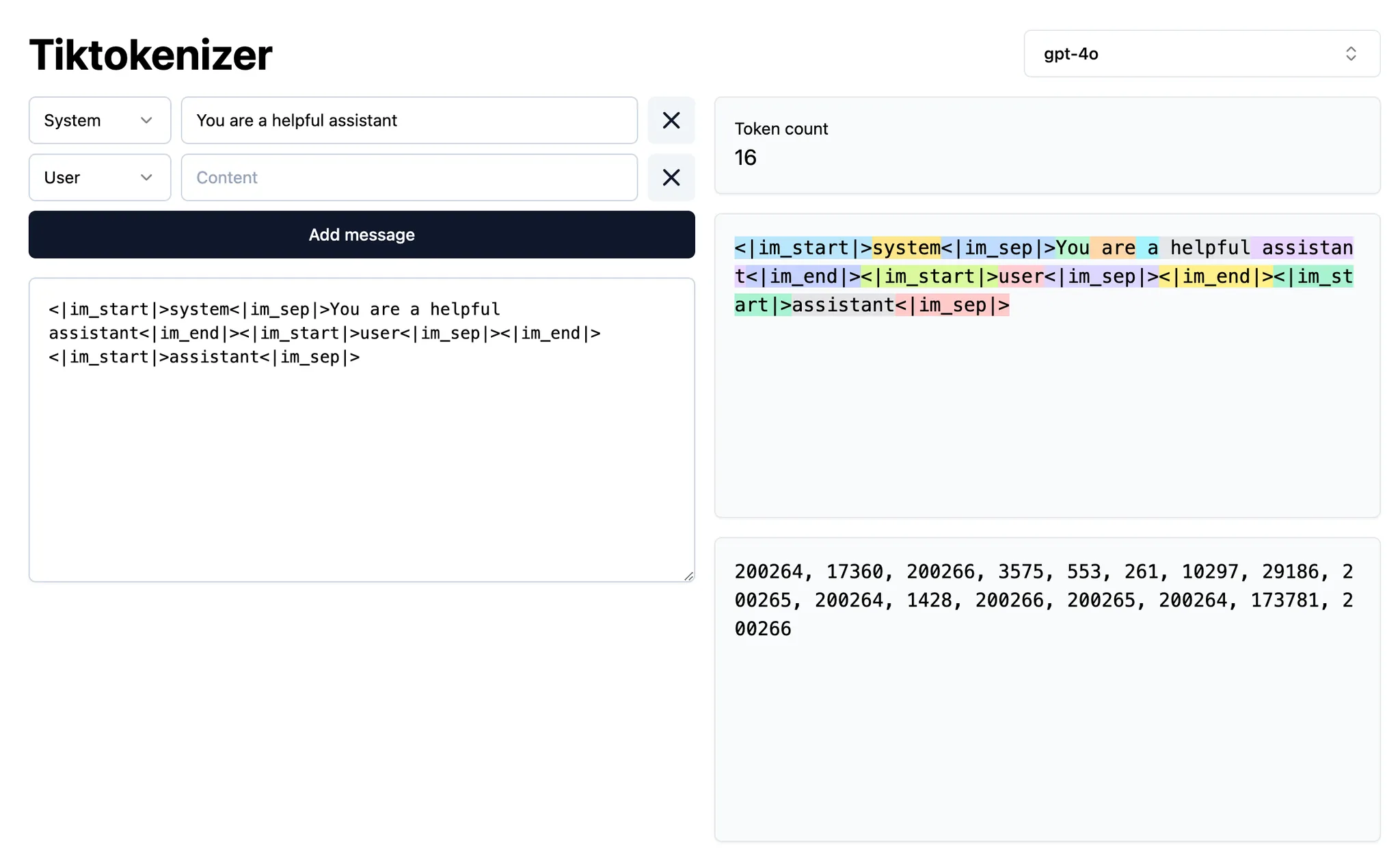
Symbole @
| Symbole | Exemple | Cas d’usage | Inconvénient |
|---|---|---|---|
@code | @LRUCachedFunction | Tu sais quelle fonction, constante ou quel symbole est pertinent pour la sortie générée | Nécessite une bonne connaissance de la base de code |
@file | cache.ts | Tu sais quel fichier doit être lu ou modifié, mais pas exactement où dans le fichier | Peut inclure beaucoup de contexte non pertinent pour la tâche selon la taille du fichier |
@folder | utils/ | Tous ou la majorité des fichiers d’un dossier sont pertinents | Peut inclure beaucoup de contexte non pertinent pour la tâche |
Règles
/Generate Cursor Rules. Si tu as eu une longue conversation en aller-retour avec beaucoup de prompts, il y a probablement des directives utiles ou des règles générales que tu voudras réutiliser plus tard.
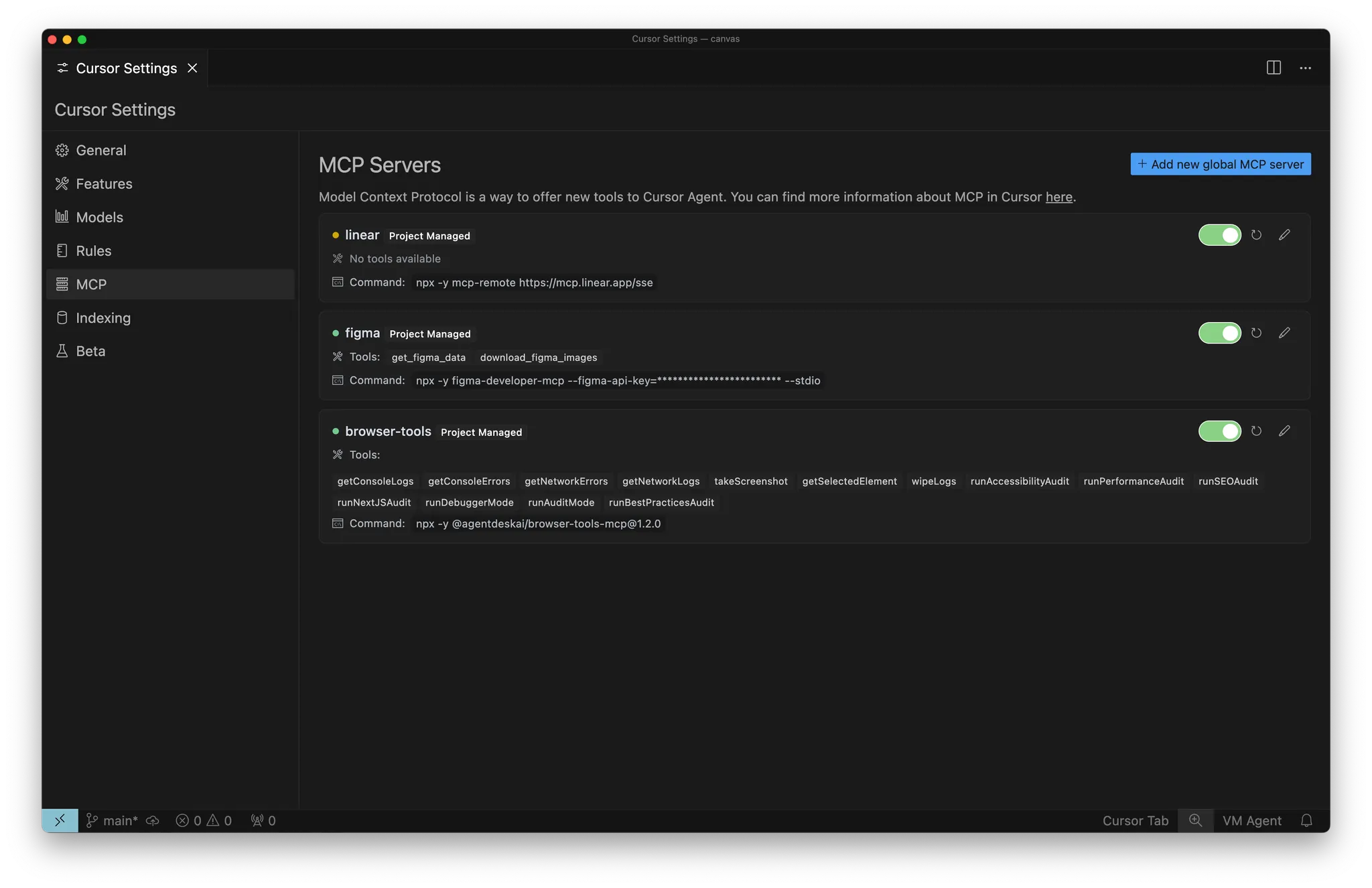
MCP
- Documentation interne : p. ex. Notion, Confluence, Google Docs
- Gestion de projet : p. ex. Linear, Jira
Auto-collecte de contexte
- Ajouter des print(“debugging: …”) aux endroits pertinents du code
- Exécuter le code ou les tests via le terminal
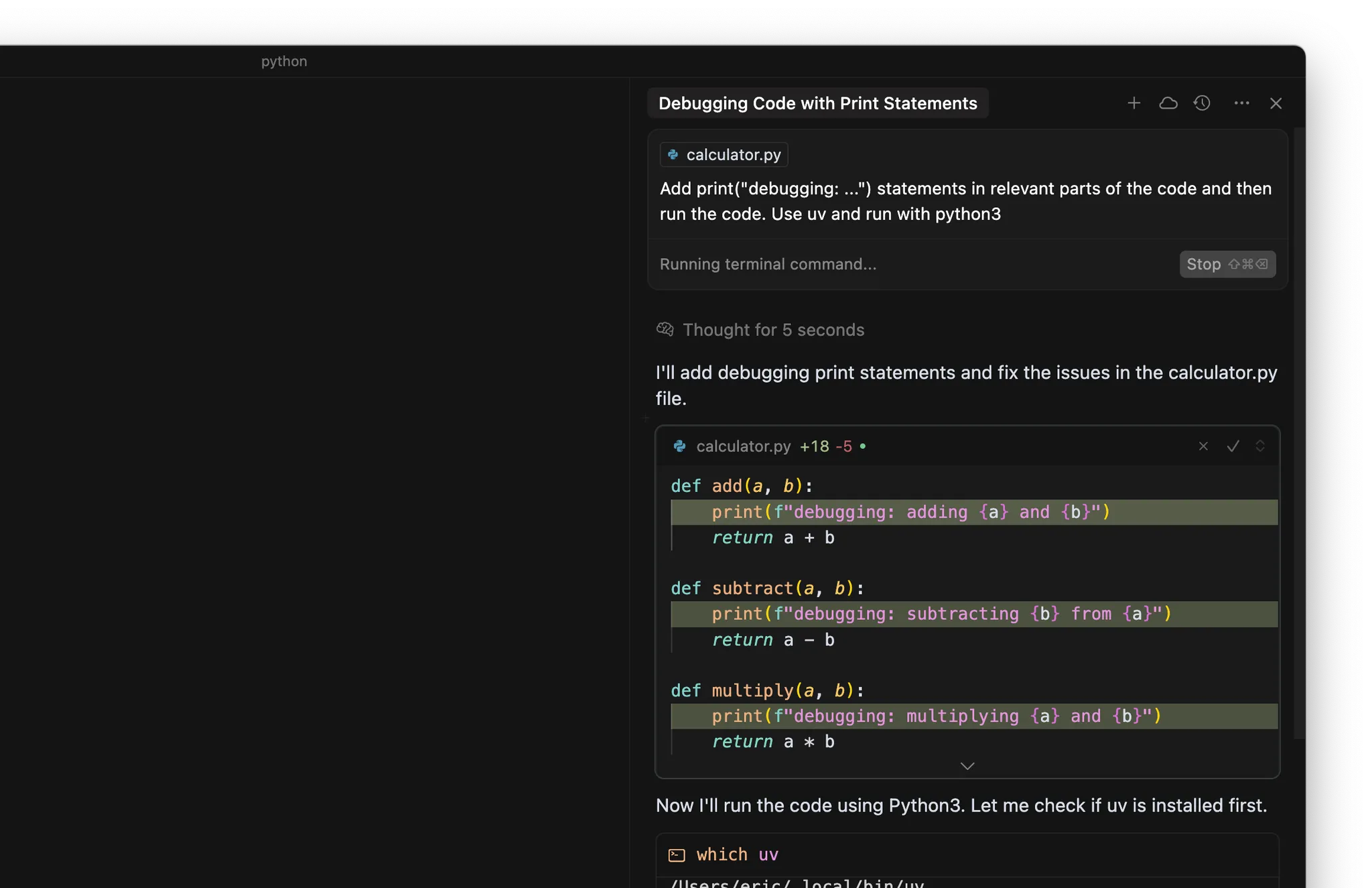
Points clés
- Le contexte est la base d’un codage IA efficace. Il se compose de l’intention (ce que tu veux) et de l’état (ce qui existe). Fournir les deux aide Cursor à faire des prédictions précises.
- Utilise un contexte chirurgical avec les symboles @ (@code, @file, @folder) pour guider Cursor avec précision, plutôt que de te reposer uniquement sur la collecte automatique de contexte.
- Capture les connaissances récurrentes dans des règles pour les réutiliser à l’échelle de l’équipe, et étends les capacités de Cursor avec le Model Context Protocol pour connecter des systèmes externes.
- Un contexte insuffisant mène à des hallucinations ou à de l’inefficacité, tandis qu’un excès de contexte non pertinent dilue le signal. Trouve le bon équilibre pour des résultats optimaux.