O que é contexto?
- Contexto de intenção define o que tu quer extrair do modelo. Por exemplo, um system prompt geralmente funciona como instruções de alto nível sobre como tu quer que o modelo se comporte. A maior parte do “prompting” feito no Cursor é contexto de intenção. “Muda aquele botão de azul pra verde” é um exemplo de intenção declarada; é prescritivo.
- Contexto de estado descreve o estado do mundo atual. Fornecer ao Cursor mensagens de erro, logs de console, imagens e trechos de código são exemplos de contexto relacionado ao estado. É descritivo, não prescritivo.
Fornecendo contexto no Cursor
- Alucinações em que o modelo tenta fazer correspondência de padrões (quando não há padrão), causando resultados inesperados. Isso pode acontecer frequentemente em modelos como o
claude-3.5-sonnetquando não recebem contexto suficiente. - O Agent tentando reunir contexto por conta própria, pesquisando o codebase, lendo arquivos e chamando ferramentas. Um modelo com raciocínio forte (como o
claude-3.7-sonnet) consegue ir bem longe com essa estratégia, e fornecer o contexto inicial certo vai determinar a trajetória.
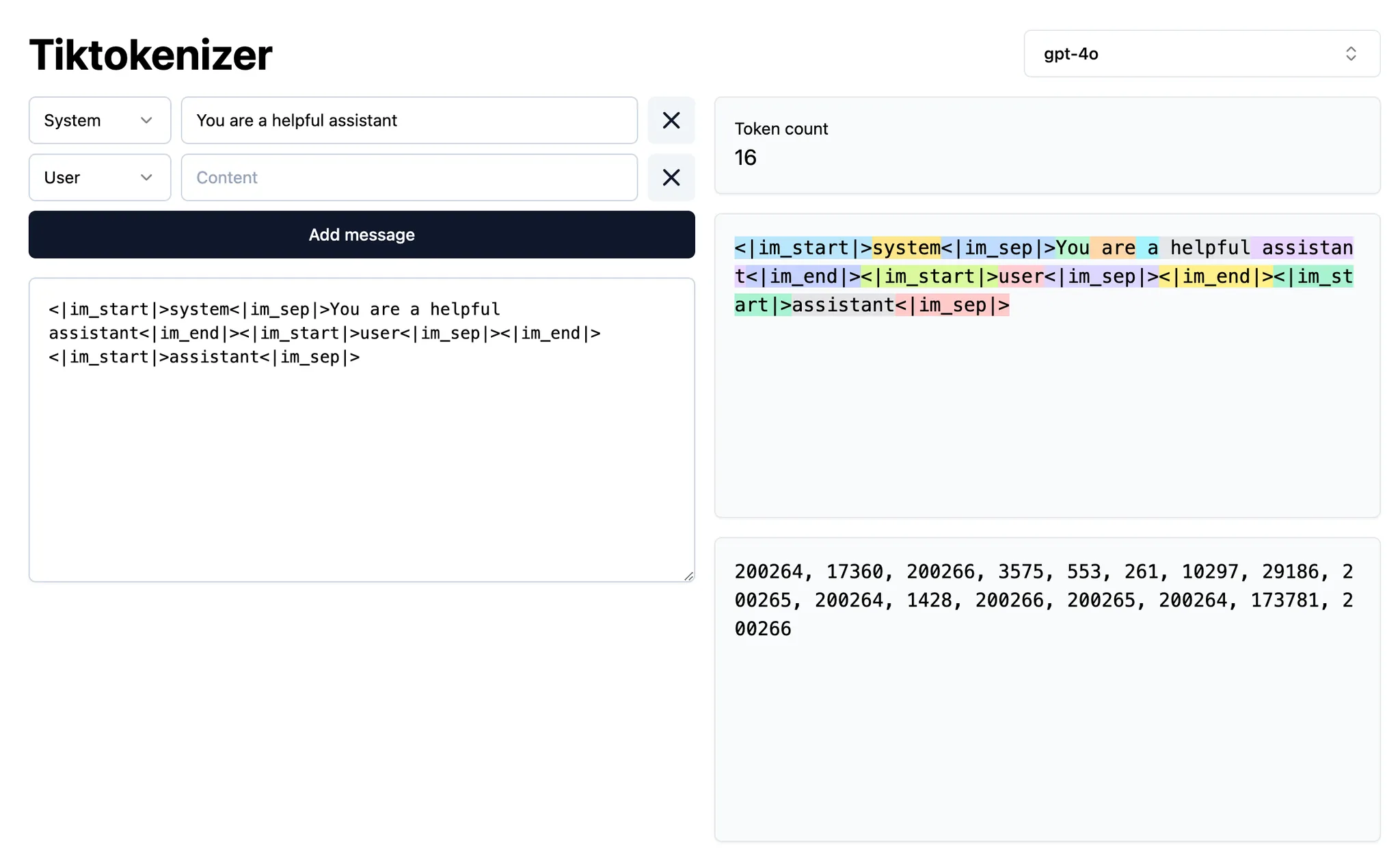
Símbolo @
| Símbolo | Exemplo | Caso de uso | Desvantagem |
|---|---|---|---|
@code | @LRUCachedFunction | Tu sabes qual função, constante ou símbolo é relevante para o resultado que tu estás gerando | Requer muito conhecimento da base de código |
@file | cache.ts | Tu sabes qual arquivo deve ser lido ou editado, mas não exatamente onde no arquivo | Pode incluir muito contexto irrelevante para a tarefa em questão, dependendo do tamanho do arquivo |
@folder | utils/ | Tudo ou a maioria dos arquivos em uma pasta é relevante | Pode incluir muito contexto irrelevante para a tarefa em questão |
Regras
/Generate Cursor Rules. Se tu teve uma conversa longa, de vai e volta, com muitos prompts, provavelmente tem algumas diretrizes úteis ou regras gerais que tu vai querer reaproveitar depois.
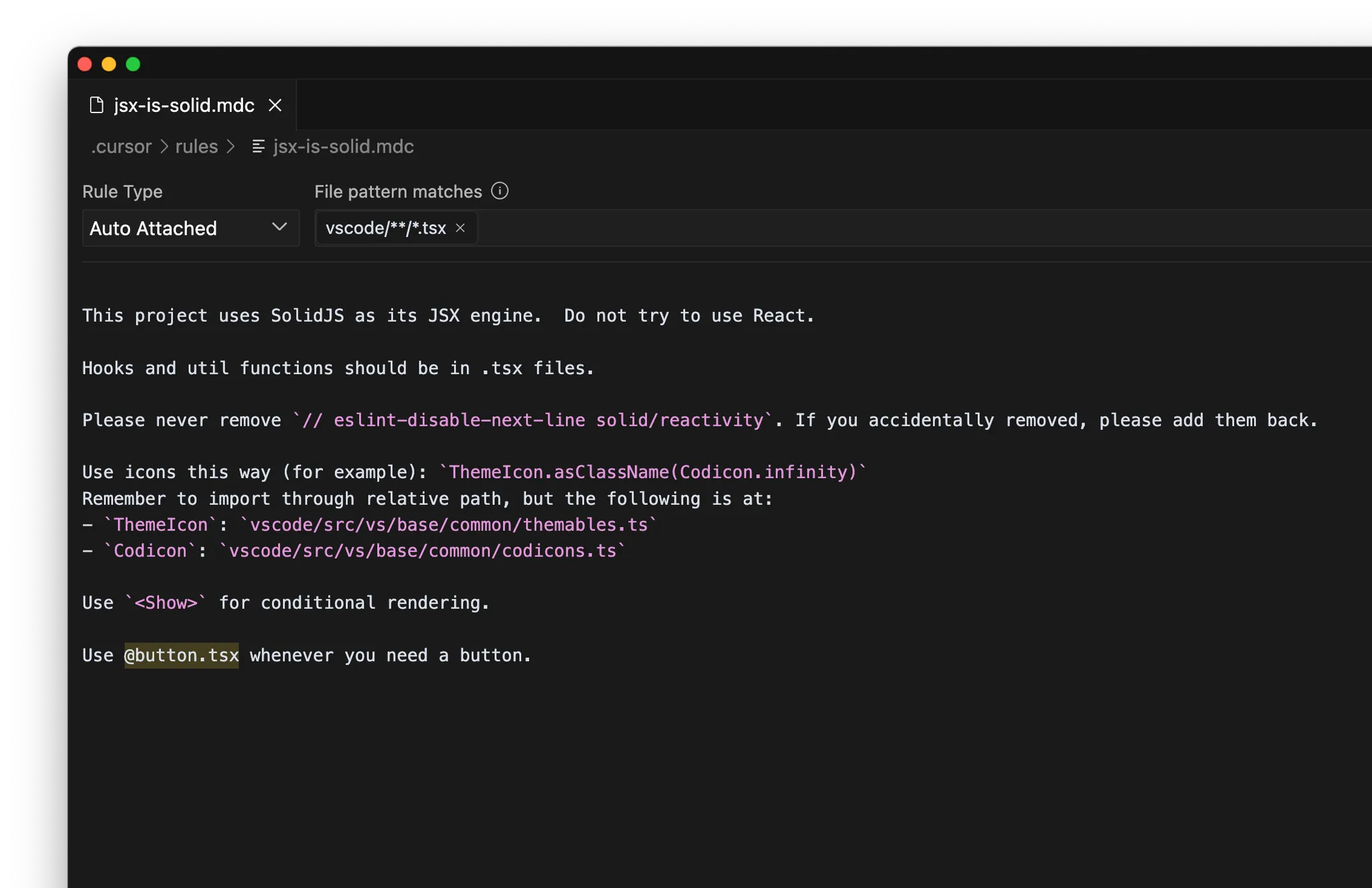
MCP
- Documentação interna: ex.: Notion, Confluence, Google Docs
- Gerenciamento de projetos: ex.: Linear, Jira
Coleta de contexto de forma autônoma
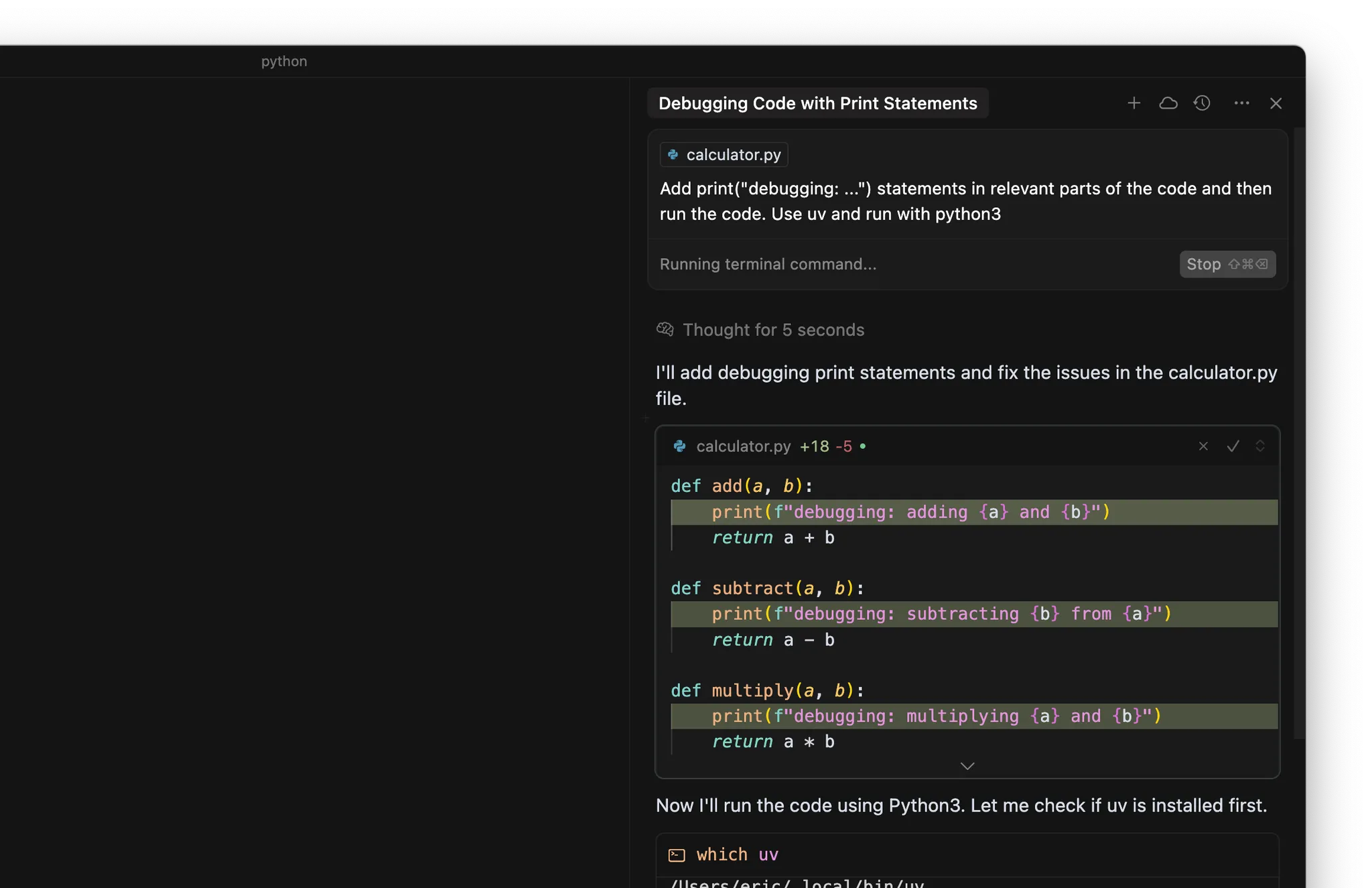
- Adicionar prints do tipo print(“debugging: …”) nas partes relevantes do código
- Rodar o código ou os testes usando o terminal
Conclusões
- Contexto é a base da programação com IA de forma eficaz, composto por intenção (o que tu queres) e estado (o que existe). Fornecer ambos ajuda o Cursor a fazer previsões precisas.
- Usa contexto cirúrgico com símbolos @ (@code, @file, @folder) para guiar o Cursor com precisão, em vez de depender só da coleta automática de contexto.
- Captura conhecimento repetível em regras para reutilização por toda a equipe e amplia as capacidades do Cursor com o Model Context Protocol para conectar sistemas externos.
- Contexto insuficiente leva a alucinações ou ineficiência, enquanto contexto demais e irrelevante dilui o sinal. Encontra o equilíbrio certo para resultados ideais.