Узнай, как настроить Cursor для рабочих процессов по data science: Python, R и SQL с ноутбуками, удалёнными средами и анализом на базе ИИ
Cursor предоставляет интегрированные инструменты для разработки в сфере data science: воспроизводимые окружения, поддержку ноутбуков и AI‑ассистента для кода. В этом руководстве разобраны основные варианты настройки для Python, R и SQL‑пайплайнов.
Для полной поддержки ноутбуков скачай расширение Jupyter (id: ms-toolsai.jupyter), опубликованное ms-toolsai.
Cursor поддерживает файлы .ipynb и .py с встроенным выполнением ячеек. Tab, Inline Edit и Agents
работают в ноутбуках так же, как и в других файлах кода.Ключевые возможности:
Выполнение ячеек inline запускает код прямо в интерфейсе редактора
Tab, Inline Edit и Agent понимают библиотеки для data science, включая pandas, NumPy, scikit-learn, а также SQL magic-команды
MCP‑серверы позволяют твоему агенту выполнять запросы напрямую к базе данных. Это даёт агенту возможность по мере необходимости обращаться к базе, писать корректный запрос, запускать команду и анализировать результаты — всё в рамках одной задачи.Например, ты можешь подключить базу данных Postgres к своему экземпляру Cursor, добавив в Cursor следующую конфигурацию MCP:
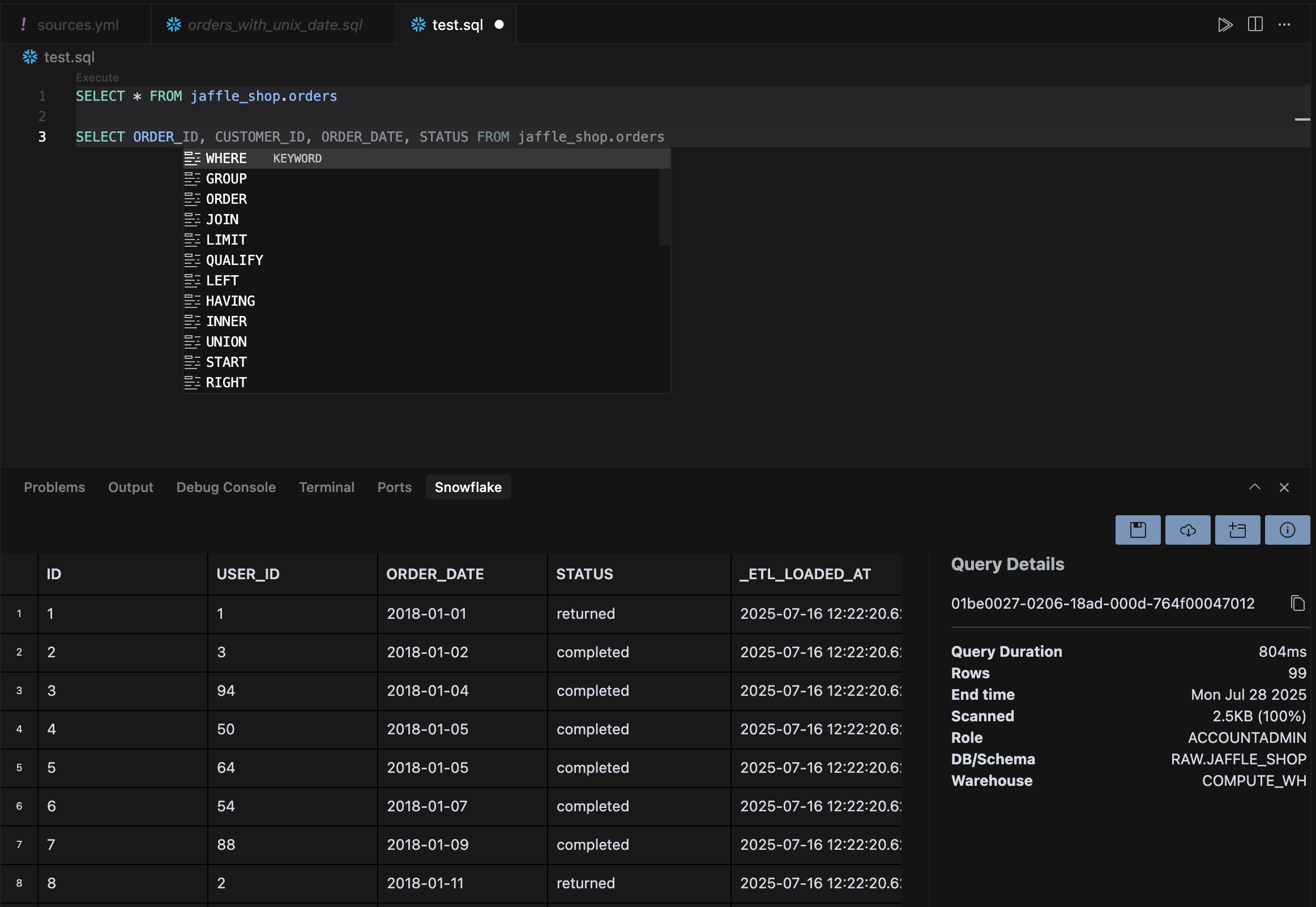
Поставь расширения для конкретных баз данных (PostgreSQL, BigQuery, SQLite, Snowflake), чтобы выполнять запросы прямо из редактора. Это убирает переключение между инструментами и включает помощь ИИ для оптимизации запросов.
Копировать
Спросить AI
-- Cursor подсказывает индексы, оконные функции и варианты оптимизации запросовSELECT user_id, event_type, COUNT(*) as event_count, RANK() OVER (PARTITION BY user_id ORDER BY COUNT(*) DESC) as frequency_rankFROM eventsWHERE created_at >= NOW() - INTERVAL '7 days'GROUP BY user_id, event_type;
Используй Агентов, чтобы анализировать медленные запросы, предлагать улучшения производительности или генерировать код визуализации для результатов запросов. Cursor понимает контекст SQL и может рекомендовать подходящие типы диаграмм на основе структуры твоих данных.
AI‑помощник Cursor работает и с библиотеками визуализации данных, включая Matplotlib, Plotly и Seaborn. Агент может генерировать код для визуализации, помогая тебе быстро и удобно исследовать данные и создавая воспроизводимый артефакт, которым легко поделиться.
Копировать
Спросить AI
import plotly.express as pximport pandas as pd# ИИ предлагает подходящие типы графиков на основе столбцов данныхdf = pd.read_csv('sales_data.csv')fig = px.scatter(df, x='advertising_spend', y='revenue', color='region', size='customer_count', title='Выручка и рекламные расходы по регионам')fig.show()
Могу ли я использовать существующие Jupyter notebooks?
Да, Cursor открывает файлы .ipynb с полной поддержкой выполнения ячеек и AI-дополнения.Как работать с большими наборами данных, которые не помещаются в память?
Используй библиотеки для распределённых вычислений, такие как Dask, или подключайся к кластерам Spark через Remote-SSH к более мощным машинам.Поддерживает ли Cursor файлы R и SQL?
Да, Cursor предоставляет AI-помощь и подсветку синтаксиса для скриптов R (.R) и файлов SQL (.sql).Как лучше делиться средами разработки?
Закоммить папку .devcontainer в систему контроля версий. Участники команды смогут автоматически пересобрать окружение при открытии проекта.Как отлаживать пайплайны обработки данных?
Используй встроенный отладчик Cursor с точками останова в Python-скриптах или задействуй Agent, чтобы пошагово анализировать и объяснять сложные преобразования данных.
Контейнеры разработки помогают обеспечить единообразные среды выполнения и зависимости для всей команды и для окружений деплоя. Они позволяют избавиться от ошибок, связанных со средой, и сокращают время онбординга для новых участников команды.Чтобы использовать контейнер разработки, сначала создай папку .devcontainer в корне репозитория. Затем создай файлы devcontainer.json, Dockerfile и requirements.txt.
# requirements.txtpandas==2.3.0numpy# добавь другие зависимости, которые нужны для твоего проекта
Cursor автоматически обнаружит devcontainer и предложит открыть проект заново внутри контейнера. Либо можно вручную открыть проект в контейнере через Command Palette (Ctrl+Shift+P) и поиск по Reopen in Container.Контейнеры для разработки дают несколько преимуществ:
Изоляция зависимостей предотвращает конфликты между проектами
Воспроизводимые сборки обеспечивают одинаковое поведение в средах разработки и продакшене
Упрощённое онбординг позволяет новым участникам команды сразу начать работу без ручной настройки
Когда для анализа нужны дополнительные вычислительные ресурсы, GPU или доступ к приватным датасетам, подключайся к удалённым машинам, сохраняя локальную среду разработки.
Разверни облачный инстанс или получи доступ к on-premises серверу с нужными ресурсами
Клонируй репозиторий на удалённую машину, включая конфигурацию .devcontainer
Подключись через Cursor: Ctrl+Shift+P → “Remote-SSH: Connect to Host”
Этот подход сохраняет единый инструментарий и позволяет масштабировать вычислительные ресурсы по мере необходимости. Одна и та же конфигурация devcontainer работает и в локальной, и в удалённой среде.