Python, R ve SQL için defterler, uzak ortamlar ve yapay zekâ destekli analizle veri bilimi iş akışlarına uygun şekilde Cursor’ı nasıl kuracağını öğren
Cursor, tekrarlanabilir ortamlar, notebook desteği ve yapay zekâ destekli kod yardımıyla veri bilimi geliştirme için entegre araçlar sunar. Bu kılavuz, Python, R ve SQL iş akışları için temel kurulum örüntülerini kapsar.
Tam notebook desteği için, ms-toolsai tarafından yayımlanan Jupyter (id: ms-toolsai.jupyter) uzantısını indir.
Cursor, entegre hücre çalıştırma ile hem .ipynb hem de .py dosyalarını destekler. Tab, Inline Edit ve Agent’lar,
diğer kod dosyalarında olduğu gibi notebook’larda da çalışır.Temel yetenekler:
Satır içi hücre çalıştırma, kodu doğrudan editör arayüzünde çalıştırır
Tab, Inline Edit ve Agent; pandas, NumPy, scikit-learn ve SQL magic komutları dahil olmak üzere veri bilimi kütüphanelerini anlar
MCP sunucuları, agent’ının sorguları doğrudan veritabanına karşı çalıştırmasına izin verir. Bu sayede agent’ın, veritabanını sorgulamayı seçebilir, uygun sorguyu yazabilir, komutu çalıştırabilir ve çıktıları analiz edebilir; tüm bunları devam eden bir görevin parçası olarak yapar.Örneğin, aşağıdaki MCP config’i Cursor’a ekleyerek bir Postgres veritabanını Cursor kurulumuna bağlayabilirsin:
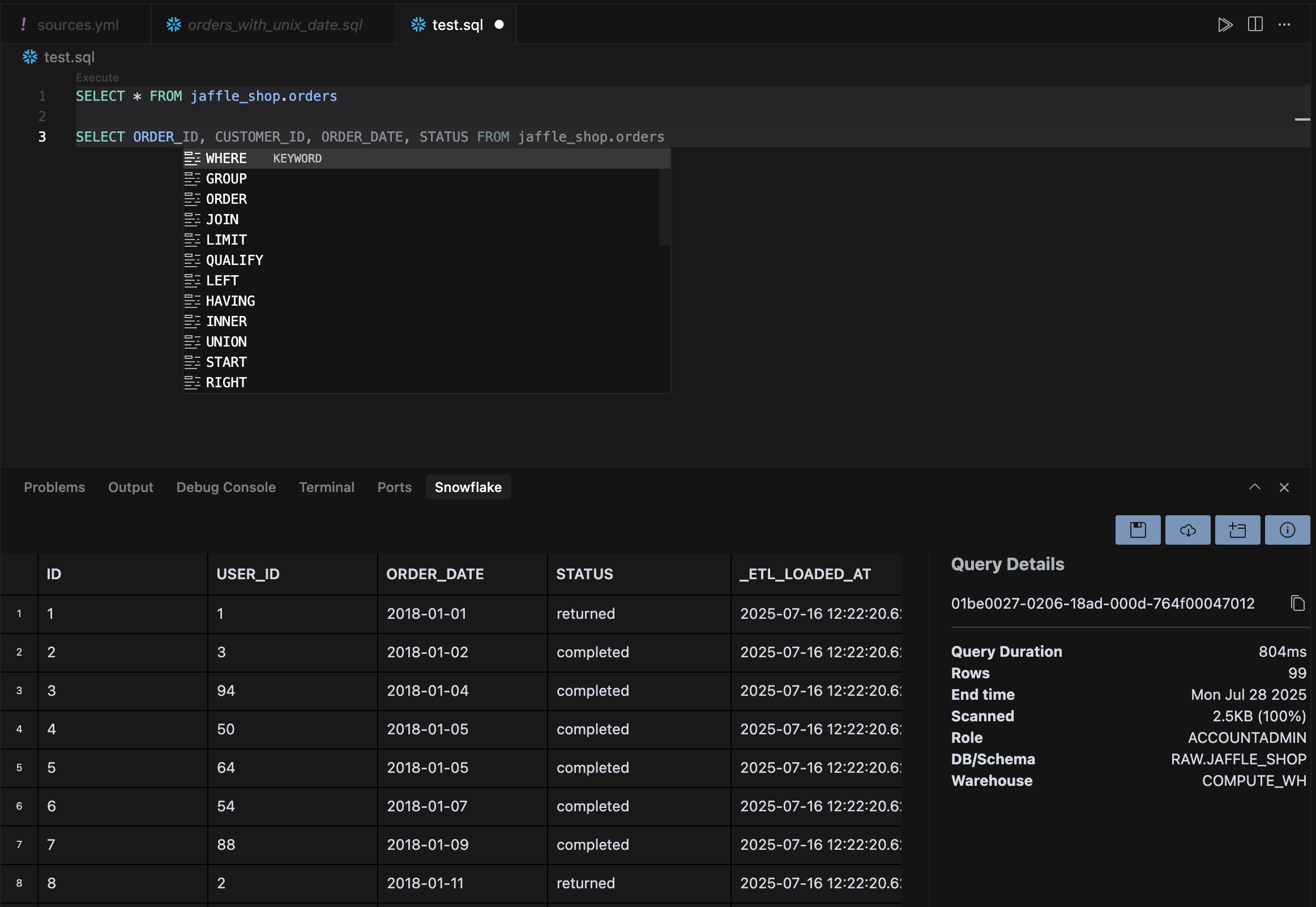
Sorguları doğrudan editörden çalıştırmak için veritabanına özel uzantıları (PostgreSQL, BigQuery, SQLite, Snowflake) yükle. Bu, araçlar arasında bağlam değiştirmeyi ortadan kaldırır ve sorgu optimizasyonu için yapay zekâ desteğini etkinleştirir.
Kopyala
AI'ya sor
-- Cursor, dizinler, pencere işlevleri ve sorgu optimizasyonu için öneriler sunarSELECT user_id, event_type, COUNT(*) as event_count, RANK() OVER (PARTITION BY user_id ORDER BY COUNT(*) DESC) as frequency_rankFROM eventsWHERE created_at >= NOW() - INTERVAL '7 days'GROUP BY user_id, event_type;
Yavaş sorguları analiz etmek, performans iyileştirmeleri önermek ya da sorgu sonuçları için görselleştirme kodu üretmek için Agents kullan. Cursor SQL bağlamını anlar ve veri yapına göre uygun grafik türlerini önerebilir.
Cursor’ın yapay zeka desteği, Matplotlib, Plotly ve Seaborn gibi veri görselleştirme kütüphanelerini de kapsar. Aracı, veri görselleştirme için kod üretebilir; böylece verileri hızlı ve kolayca keşfetmene yardımcı olurken, yeniden üretilebilir ve paylaşılabilir bir çıktı oluşturur.
Kopyala
AI'ya sor
import plotly.express as pximport pandas as pd# Yapay zeka, veri sütunlarına göre uygun grafik türlerini önerirdf = pd.read_csv('sales_data.csv')fig = px.scatter(df, x='advertising_spend', y='revenue', color='region', size='customer_count', title='Bölgeler Bazında Gelir ve Reklam Harcaması'fig.show()
Mevcut Jupyter notebook’larını kullanabilir miyim?
Evet, Cursor .ipynb dosyalarını tam hücre çalıştırma ve AI tamamlama desteğiyle açar.Belleğe sığmayan büyük veri kümelerini nasıl yönetirim?
Dask gibi dağıtık hesaplama kütüphanelerini kullan ya da daha büyük makinelere Remote-SSH bağlantıları üzerinden Spark kümelerine bağlan.Cursor R ve SQL dosyalarını destekliyor mu?
Evet, Cursor R betikleri (.R) ve SQL dosyaları (.sql) için AI yardımı ve sözdizimi vurgulaması sağlar.Geliştirme ortamlarını paylaşmanın önerilen yolu nedir?.devcontainer klasörünü sürüm kontrolüne ekle. Ekip üyeleri projeyi açtığında ortamı otomatik olarak yeniden oluşturabilir.Veri işleme hatlarını nasıl hata ayıklarım?
Cursor’ın tümleşik hata ayıklayıcısını Python betiklerinde kesme noktalarıyla kullan ya da Agent’tan karmaşık veri dönüşümlerini adım adım analiz edip açıklamasını iste.
Geliştirme konteynerları, ekip üyeleri ve dağıtım ortamları arasında tutarlı çalışma zamanları ve bağımlılıklar sağlamana yardımcı olur. Ortama özgü hataları ortadan kaldırabilir ve yeni ekip üyeleri için işe alıştırma süresini kısaltabilirler.Bir geliştirme konteynerı kullanmak için, depo kökünde bir .devcontainer klasörü oluşturarak başla. Ardından devcontainer.json, Dockerfile ve requirements.txt dosyalarını oluştur.
# requirements.txtpandas==2.3.0numpy# projen için gereken diğer bağımlılıkları ekle
Cursor devcontainer’ı otomatik olarak algılar ve projeni bir container içinde yeniden açman için seni yönlendirir. İstersen, Command Palette’i (Ctrl+Shift+P) açıp Reopen in Container komutunu arayarak elle de container içinde yeniden açabilirsin.Geliştirme container’ları bir dizi avantaj sağlar:
Bağımlılık izolasyonu, projeler arasında çakışmaları önler
Yineleyebilir derlemeler, geliştirme ve üretim ortamları arasında tutarlı davranış sağlar
Kolaylaştırılmış onboarding, yeni ekip üyelerinin manuel kurulum olmadan hemen başlamasını sağlar
Analizin ek hesaplama kaynakları, GPU’lar veya özel veri kümelerine erişim gerektirdiğinde, yerel geliştirme ortamını koruyarak uzak makinelerine bağlan.
Gerekli kaynaklara sahip bir bulut instance’ı ayarla veya şirket içi bir sunucuya eriş
.devcontainer yapılandırması dahil repoyu uzak makineye klonla
Cursor üzerinden bağlan: Ctrl+Shift+P → “Remote-SSH: Connect to Host”
Bu yaklaşım, gerektiğinde hesaplama kaynaklarını ölçeklendirirken tutarlı araç setini korur. Aynı geliştirme container yapılandırması hem yerel hem de uzak ortamlarda çalışır.