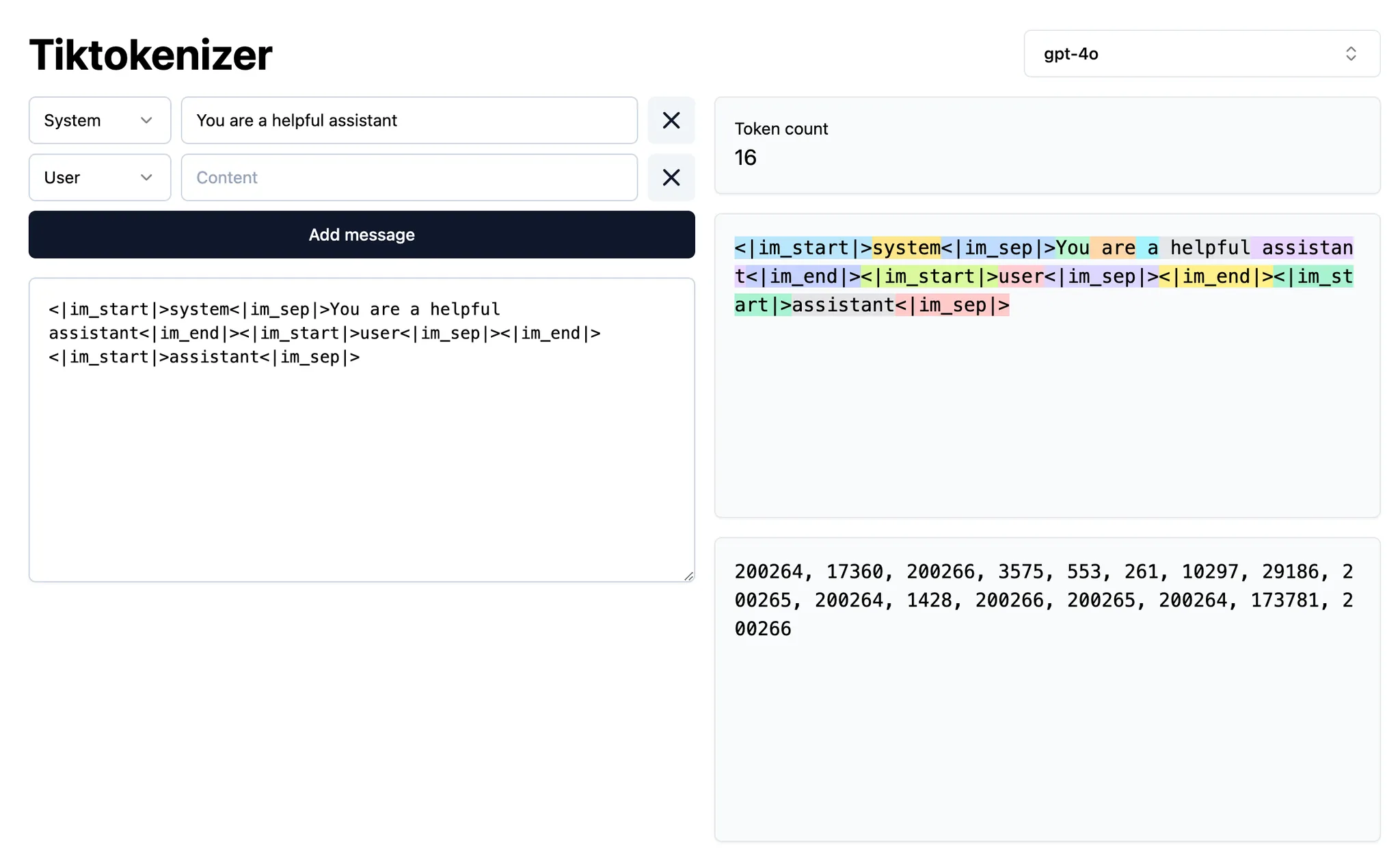
什麼是 context?
- Intent context 定義使用者想讓模型達成的目標。比如,system prompt 通常提供高層級的指示,描述使用者希望模型如何行為。在 Cursor 中,大多數的「prompting」都屬於 intent context。「把那個按鈕從藍色改成綠色」就是一個明確的意圖;它是具指示性的。
- State context 描述當前的狀態。提供 Cursor 錯誤訊息、console logs、圖片,以及程式碼片段,都是與狀態相關的 context 範例。它是描述性的,而非指示性的。
在 Cursor 中提供脈絡
- 產生幻覺:模型在沒有模式時硬做模式匹配,結果出乎意料。像
claude-3.5-sonnet這類模型在脈絡不足時特別常見。 - Agent 會自己想辦法蒐集脈絡,例如搜尋程式碼庫、讀檔、呼叫工具。強思考模型(像
claude-3.7-sonnet)用這招能走很遠,而是否給對初始脈絡,會決定整體走向。
@-符號
| 符號 | 範例 | 使用情境 | 缺點 |
|---|---|---|---|
@code | @LRUCachedFunction | 你知道哪個 function、constant 或 symbol 和你要產生的輸出最相關 | 需要對整個 codebase 有相當多的了解 |
@file | cache.ts | 你知道要讀或要編輯哪個檔案,但不確定在檔案裡的確切位置 | 視檔案大小而定,可能會把對目前任務不相關的脈絡一起帶進來 |
@folder | utils/ | 某個資料夾中的全部或大多數檔案都與任務相關 | 可能會包含大量與目前任務不相關的脈絡 |
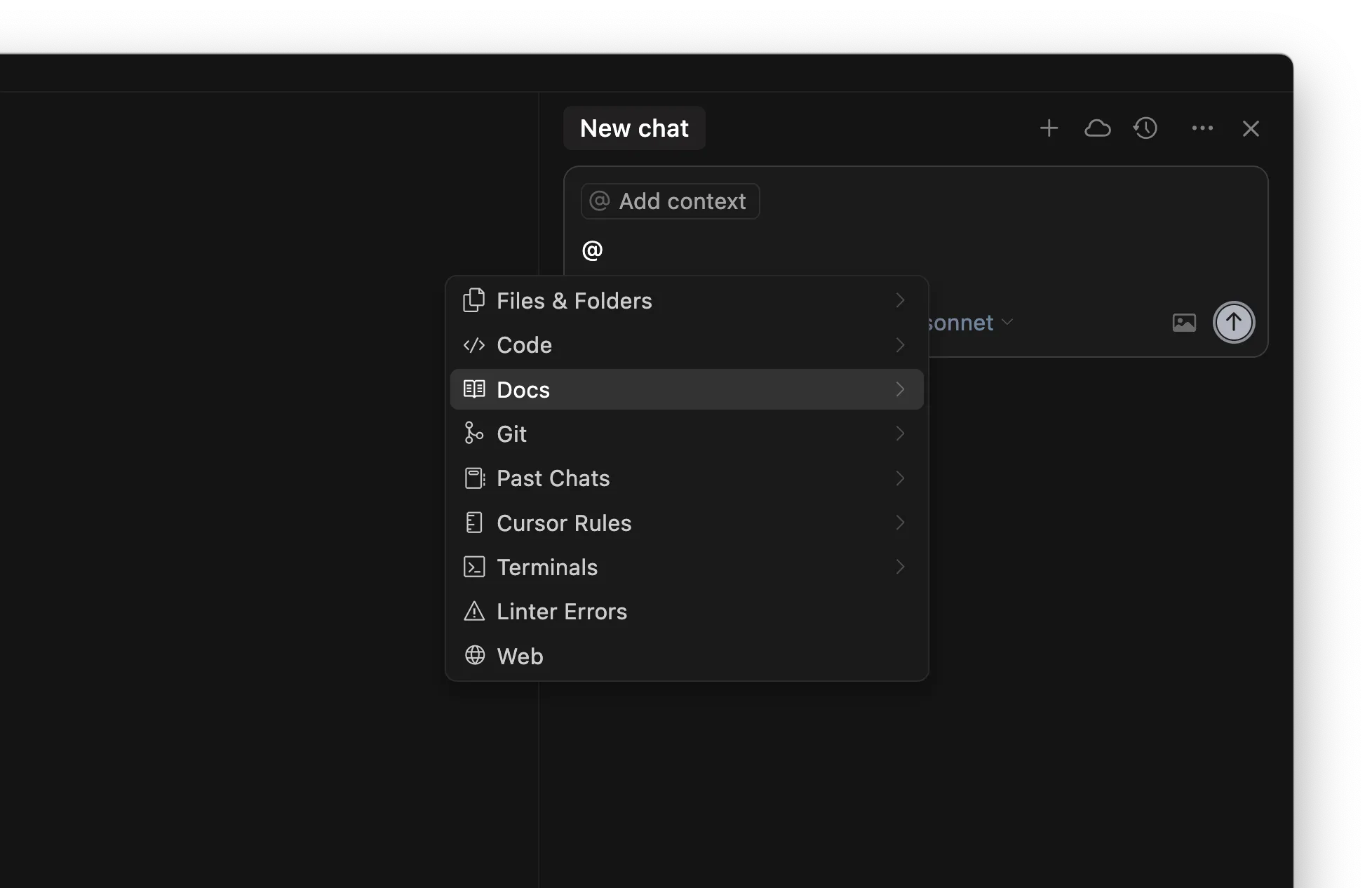
規則
/Generate Cursor Rules 從現有對話產生規則。如果你有一段很長、包含許多提示的來回對話,裡面很可能有一些實用的指示或通用規則,之後可以重複利用。
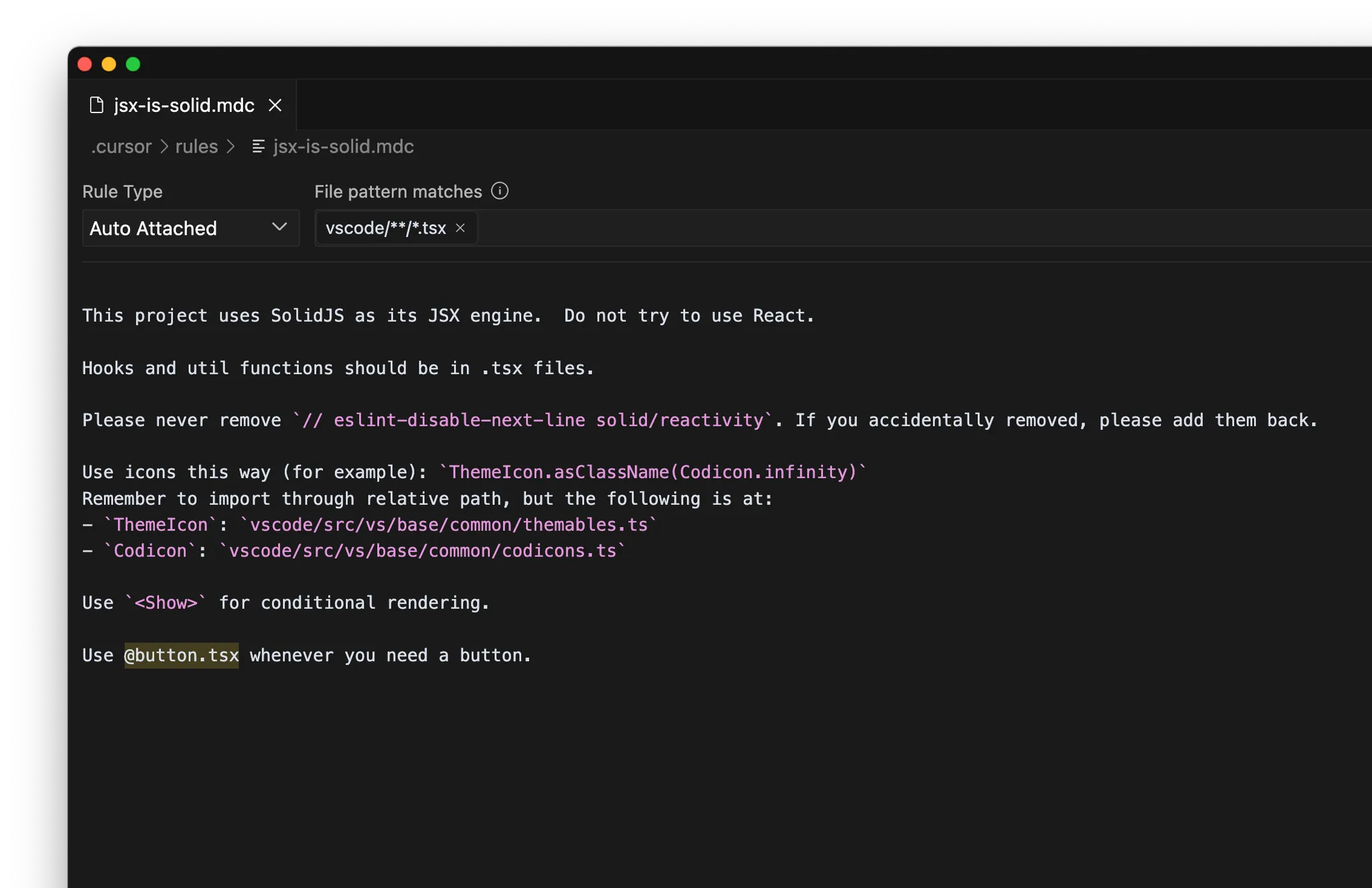
MCP
- 內部文件:例如 Notion、Confluence、Google 文件
- 專案管理:例如 Linear、Jira
自我蒐集脈絡
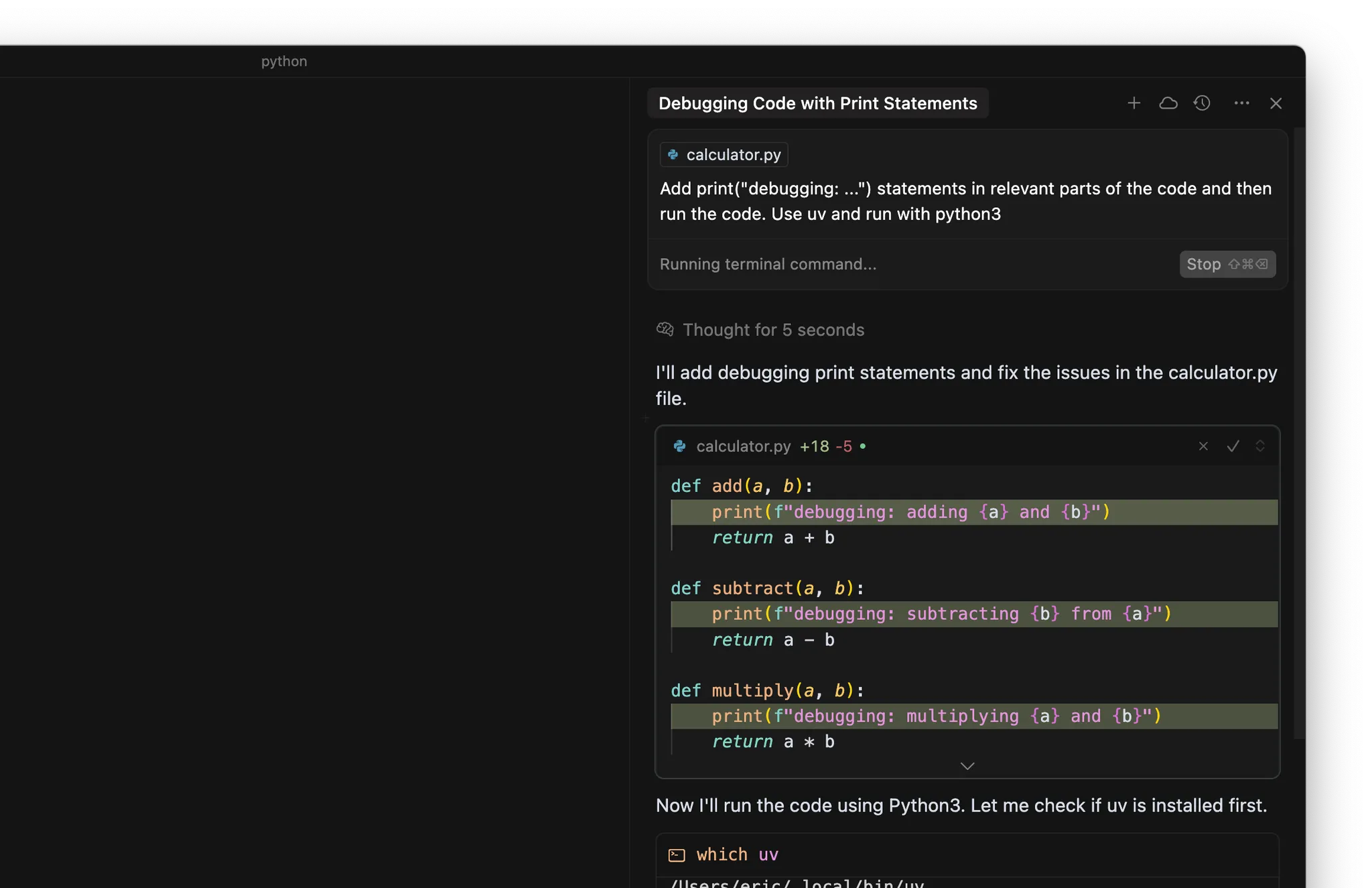
- 在程式碼相關位置加入 print(“debugging: …”) 陳述式
- 用終端機執行程式或測試
重點摘要
- Context 是高效 AI 寫程式的基礎,由 intent(你想做什麼)和 state(目前有哪些東西)組成。同時提供兩者能幫助 Cursor 做出更準確的預測。
- 用帶有 @ 符號的「精準 context」(@code、@file、@folder)來精確引導 Cursor,而不是只依賴自動收集的 context。
- 把可重複的知識整理成 rules,讓整個團隊共用,並透過 Model Context Protocol 擴充 Cursor 的能力以串接外部系統。
- Context 不足會導致幻覺或效率低下;過多無關的 context 會稀釋訊號。拿捏好平衡,才能拿到最佳效果。