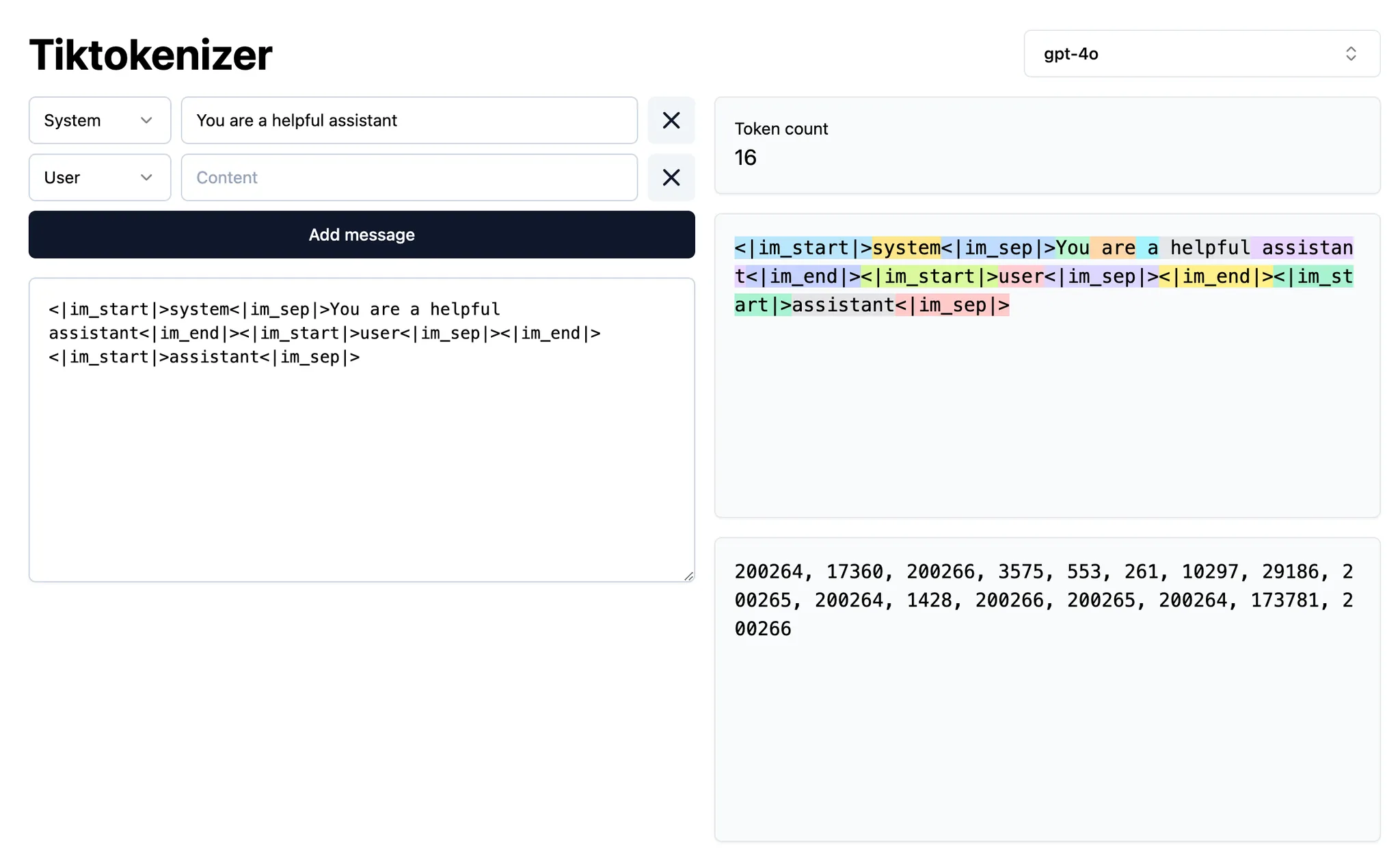
什么是 context?
- Intent context 用来定义用户想让模型达成的目标。比如,system prompt 通常作为高层级指令,规定模型应该如何行为。在 Cursor 里,大多数“prompting”都属于 intent context。“把那个按钮从蓝色改成绿色”就是一个明确的意图示例;它是规定性的。
- State context 用来描述当前的状态。把错误信息、控制台日志、图片以及代码片段提供给 Cursor,都是与状态相关的 context 示例。它是描述性的,而非规定性的。
在 Cursor 中提供上下文
- 幻觉:在不存在规律时盲目进行模式匹配,从而产生意外结果。对于像
claude-3.5-sonnet这样的模型,如果缺少足够的上下文,这种情况会更常见。 - Agent 会尝试自行收集上下文,比如搜索代码库、读取文件、调用工具。一个推理能力强的模型(例如
claude-3.7-sonnet)在这种策略下也能走得很远,而是否提供了正确的初始上下文将决定其后续走向。
@-symbol
| Symbol | Example | Use case | Drawback |
|---|---|---|---|
@code | @LRUCachedFunction | 你知道哪个函数、常量或符号和你要生成的输出最相关 | 需要对代码库有很深的了解 |
@file | cache.ts | 你知道应该读取或编辑哪个文件,但不确定在文件中的具体位置 | 可能会根据文件大小为当前任务引入大量无关上下文 |
@folder | utils/ | 该文件夹中的全部或大部分文件都相关 | 可能会为当前任务引入大量无关上下文 |
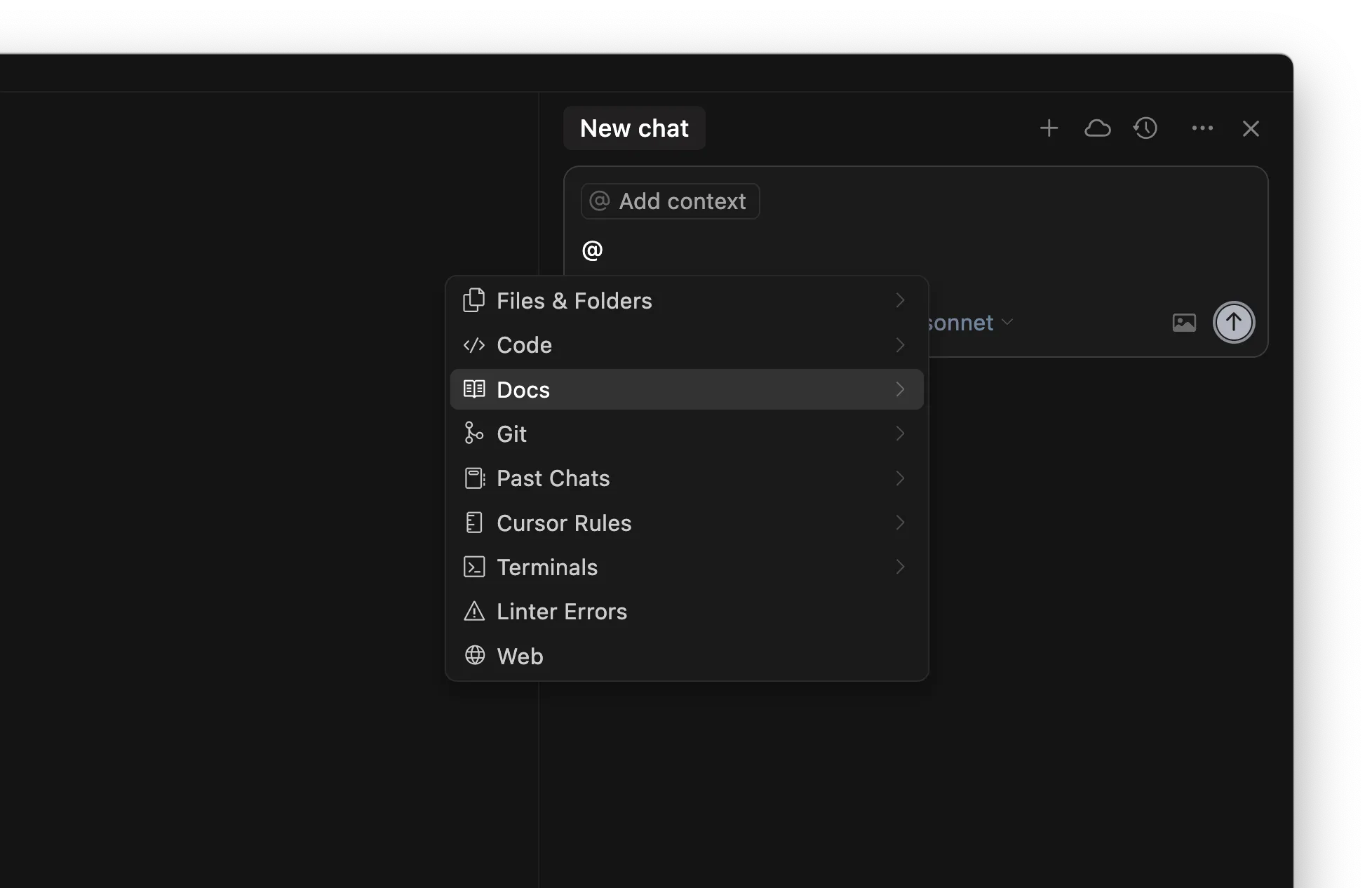
规则
/Generate Cursor Rules 从现有对话生成规则。如果有一段往返很多、提示很密集的长对话,里面很可能有以后想复用的有用指令或通用规则。
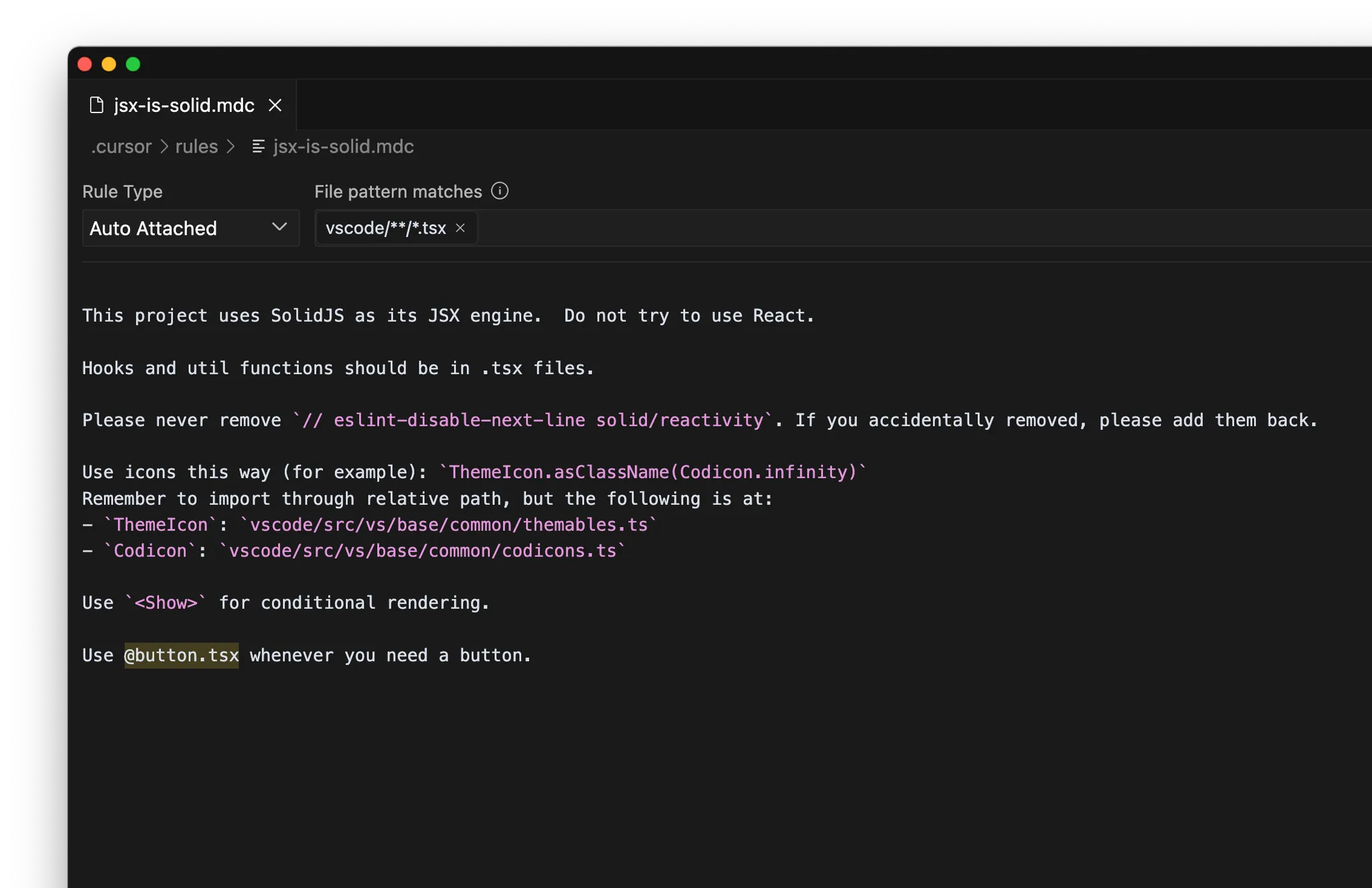
MCP
- 内部文档:如 Notion、Confluence、Google Docs
- 项目管理:如 Linear、Jira
自主收集上下文
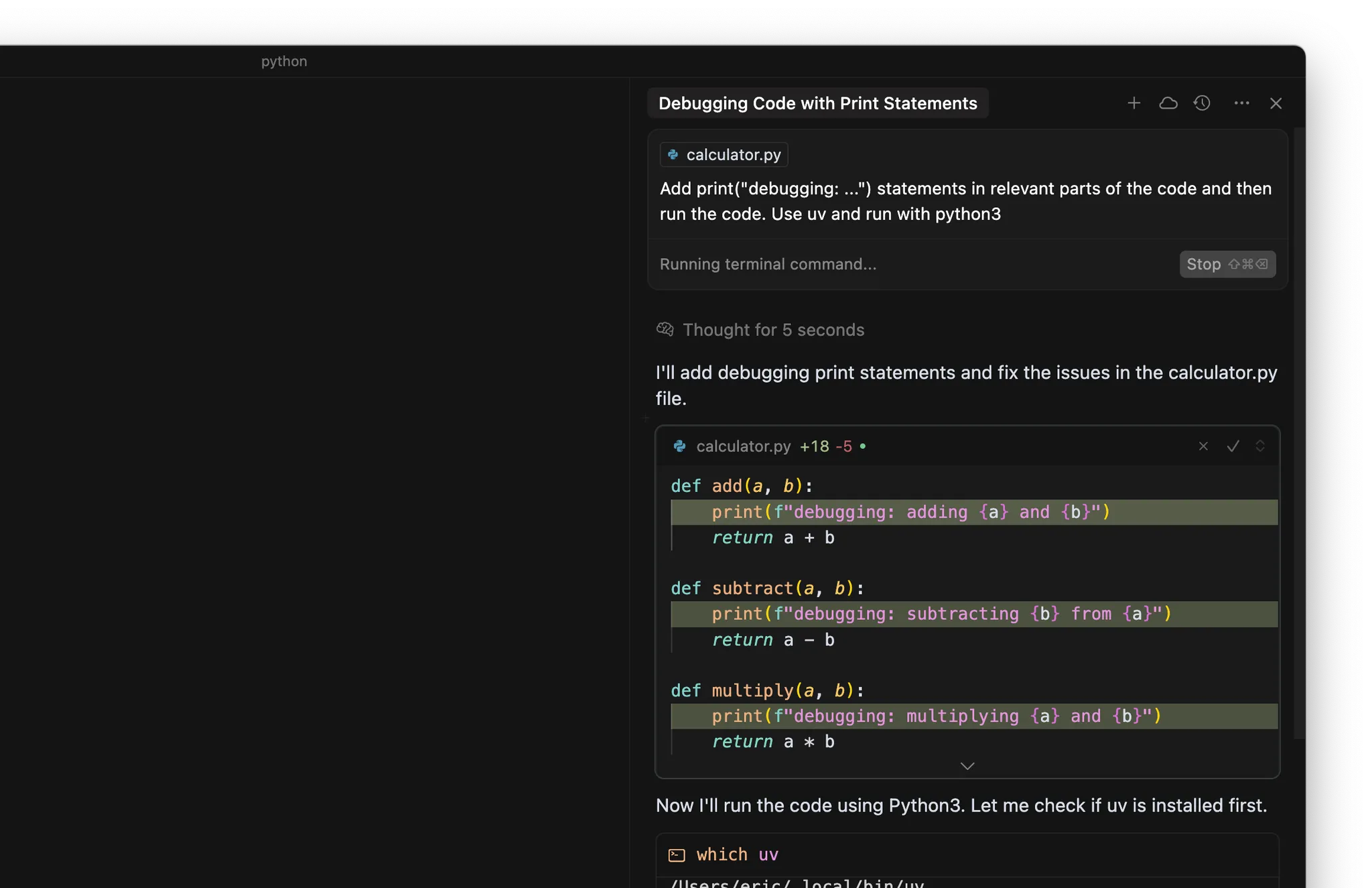
- 在代码的相关位置添加 print(“debugging: …”) 语句
- 使用终端运行代码或测试
关键要点
- 上下文是高效 AI 编码的基础,由意图(想做什么)和状态(现有内容)构成,同时提供两者能帮助 Cursor 做出更准确的预测。
- 使用带 @ 的精确上下文(@code、@file、@folder)来有的放矢地引导 Cursor,而不是只依赖自动上下文收集。
- 将可复用的知识沉淀为规则,便于团队范围内复用,并通过 Model Context Protocol 扩展 Cursor 的能力以连接外部系统。
- 上下文不足会导致幻觉或低效,过多无关上下文会稀释信号;把握合适的平衡以获得最佳效果。