¿Qué es el contexto?
- Contexto de intención define lo que el usuario quiere obtener del modelo. Por ejemplo, un system prompt normalmente sirve como instrucciones de alto nivel sobre cómo el usuario quiere que el modelo se comporte. La mayor parte del “prompting” que se hace en Cursor es contexto de intención. “Cambia ese botón de azul a verde” es un ejemplo de intención declarada; es prescriptivo.
- Contexto de estado describe el estado del mundo actual. Proporcionar a Cursor mensajes de error, registros de consola, imágenes y fragmentos de código son ejemplos de contexto relacionado con el estado. Es descriptivo, no prescriptivo.
Proporcionar contexto en Cursor
- Alucinaciones donde el modelo intenta hacer pattern matching (cuando no hay un patrón), lo que provoca resultados inesperados. Esto puede suceder con frecuencia en modelos como
claude-3.5-sonnetcuando no reciben suficiente contexto. - El Agent intentando reunir contexto por su cuenta buscando en el código, leyendo archivos y llamando a herramientas. Un modelo con strong thinking (como
claude-3.7-sonnet) puede llegar bastante lejos con esta estrategia, y proporcionar el contexto inicial correcto marcará la trayectoria.
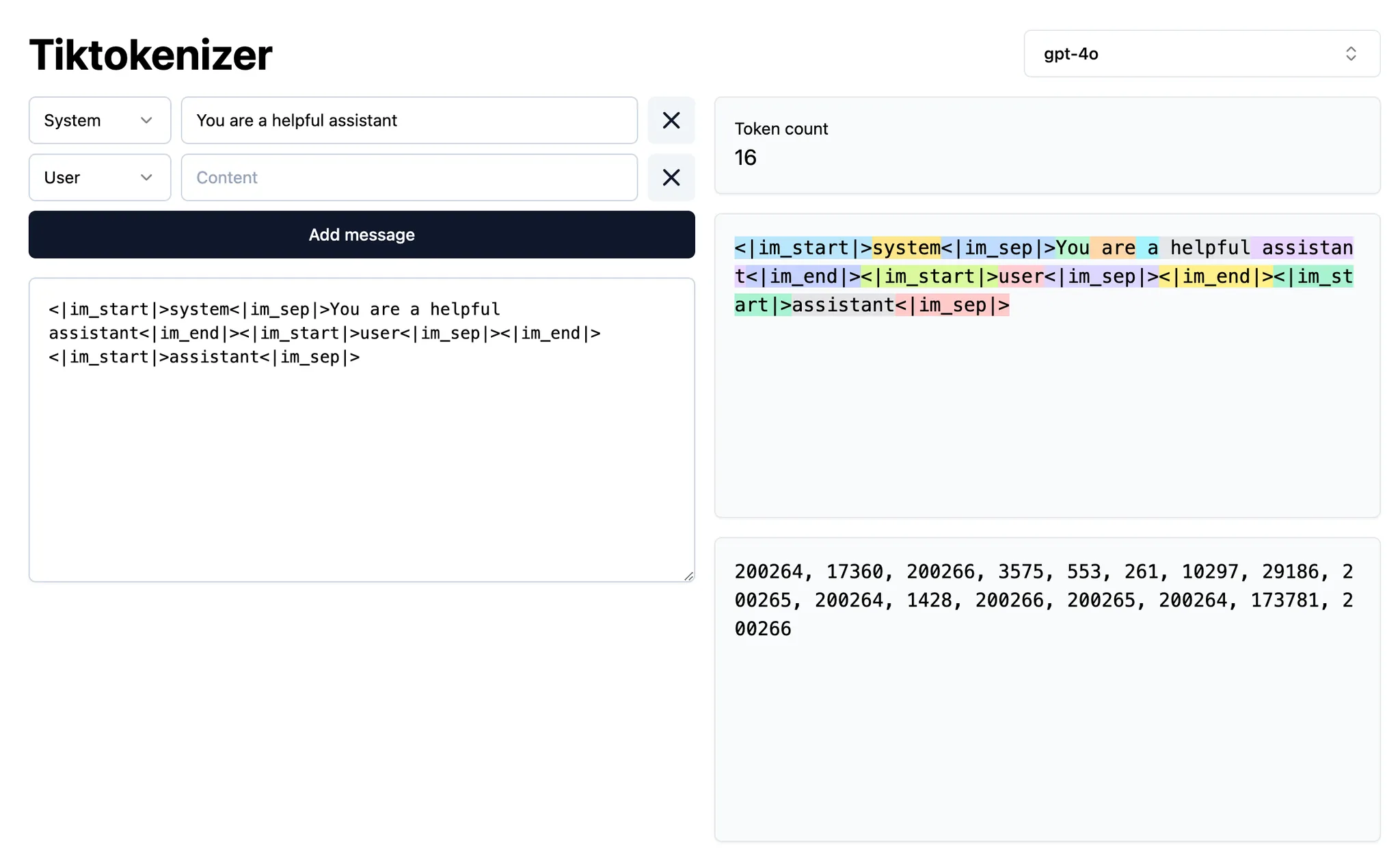
Símbolo @
| Símbolo | Ejemplo | Caso de uso | Desventaja |
|---|---|---|---|
@code | @LRUCachedFunction | Sabes qué función, constante o símbolo es relevante para el resultado que estás generando | Requiere conocer muy bien la base de código |
@file | cache.ts | Sabes qué archivo debe leerse o editarse, pero no exactamente en qué parte del archivo | Puede incluir mucho contexto irrelevante para la tarea en cuestión según el tamaño |
@folder | utils/ | Todo o la mayoría de los archivos de una carpeta son relevantes | Puede incluir mucho contexto irrelevante para la tarea en cuestión |
Reglas
/Generate Cursor Rules. Si tuviste una conversación larga, con mucho ida y vuelta y muchos prompts, probablemente haya directrices útiles o reglas generales que quieras reutilizar después.
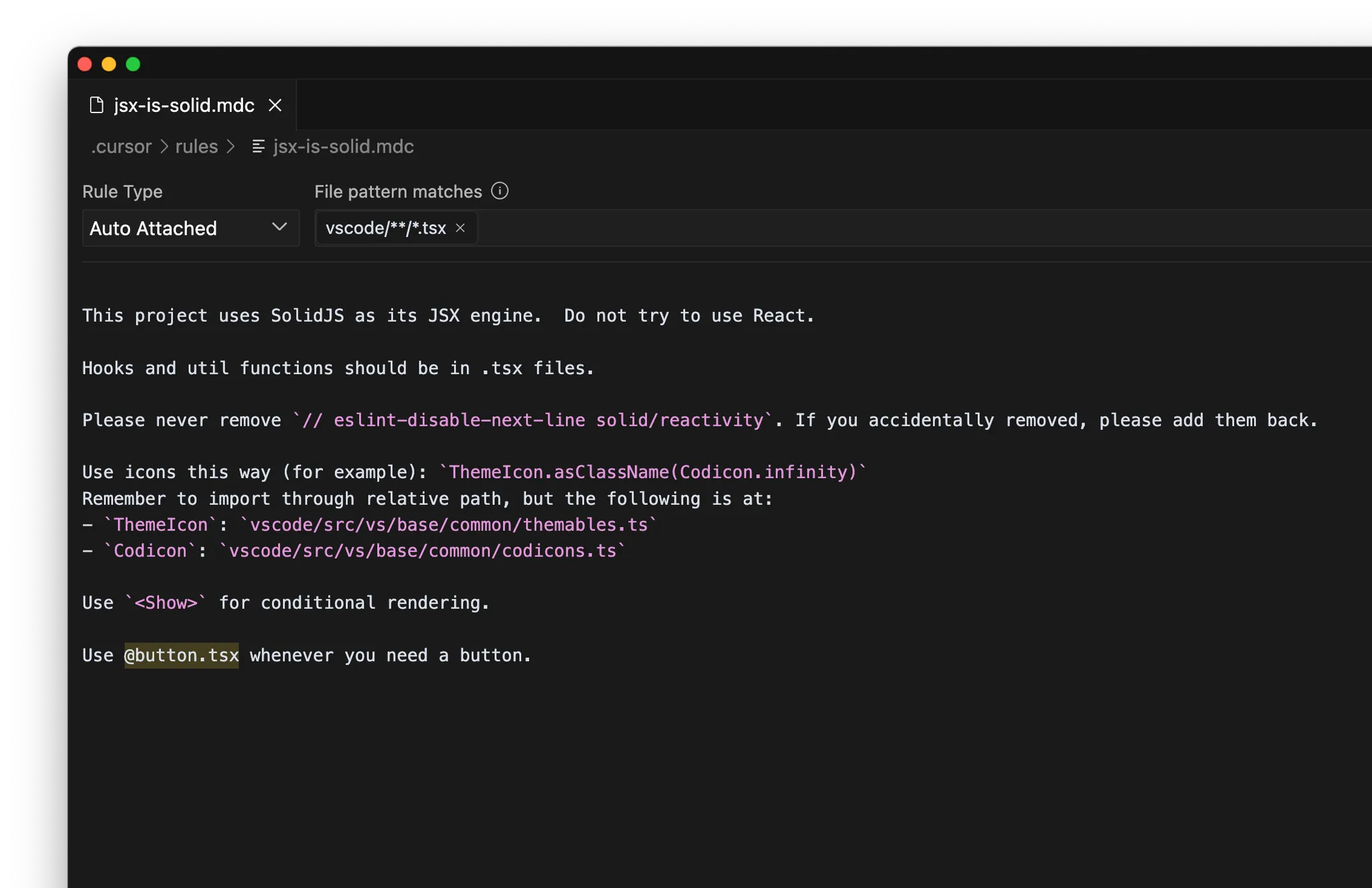
MCP
- Documentación interna: p. ej., Notion, Confluence, Google Docs
- Gestión de proyectos: p. ej., Linear, Jira
Auto-recolección de contexto
- Añada print(“debugging: …”) en partes relevantes del código
- Ejecute el código o las pruebas usando la terminal
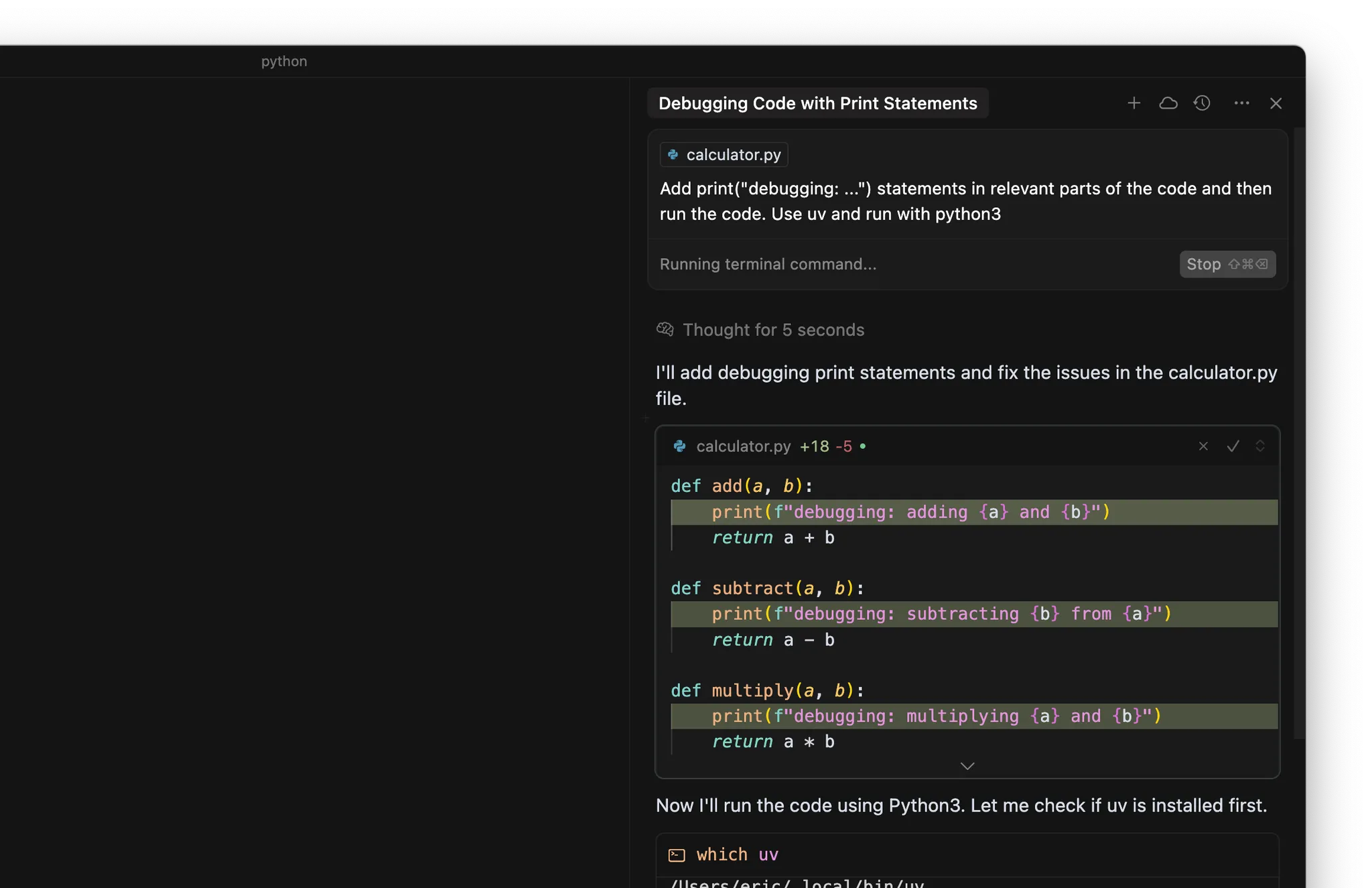
Conclusiones
- El contexto es la base de una codificación con IA efectiva y está compuesto por la intención (lo que querés) y el estado (lo que existe). Incluir ambos ayuda a Cursor a hacer predicciones precisas.
- Usá contexto quirúrgico con símbolos @ (@code, @file, @folder) para guiar a Cursor con precisión, en vez de depender solo de la recolección automática de contexto.
- Capturá el conocimiento repetible en reglas para reutilizarlo a nivel de equipo y ampliá las capacidades de Cursor con Model Context Protocol para conectar sistemas externos.
- Un contexto insuficiente lleva a alucinaciones o ineficiencia, mientras que demasiado contexto irrelevante diluye la señal. Encontrá el equilibrio adecuado para obtener resultados óptimos.