컨텍스트란 뭐야?
- 의도 컨텍스트는 사용자가 모델에서 얻고 싶은 걸 정의해. 예를 들어 시스템 프롬프트는 보통 사용자가 모델이 어떻게 행동하길 원하는지에 대한 상위 수준의 지침 역할을 해. Cursor에서 이루어지는 대부분의 “프롬프트 입력”은 의도 컨텍스트야. “그 버튼을 파란색에서 초록색으로 바꿔줘” 같은 건 명시된 의도의 예시고, 처방적이야.
- 상태 컨텍스트는 현재 환경의 상태를 설명해. Cursor에 에러 메시지, 콘솔 로그, 이미지, 코드 조각을 제공하는 건 상태와 관련된 컨텍스트의 예시야. 이건 처방적이 아니라 서술적이야.
Cursor에서 컨텍스트 제공하기
- 패턴이 없는데도 모델이 패턴 매칭을 시도하면서 생기는 환각. 컨텍스트가 부족하면
claude-3.5-sonnet같은 모델에서 자주 일어날 수 있어. - Agent가 코드를 검색하고, 파일을 읽고, 툴을 호출해서 스스로 컨텍스트를 모으려는 시도. 강력한 사고 모델(예:
claude-3.7-sonnet)은 이 전략만으로도 꽤 멀리 갈 수 있고, 올바른 초기 컨텍스트가 있으면 진행 궤적이 결정돼.
@-기호
| Symbol | Example | Use case | Drawback |
|---|---|---|---|
@code | @LRUCachedFunction | 생성하려는 출력과 관련된 함수, 상수, 혹은 심볼을 정확히 알고 있을 때 | 코드베이스 전반에 대한 높은 이해가 필요함 |
@file | cache.ts | 어떤 파일을 읽거나 수정해야 하는지는 알지만, 파일 내 정확한 위치는 모를 때 | 파일 크기에 따라 현재 작업과 무관한 컨텍스트가 많이 포함될 수 있음 |
@folder | utils/ | 폴더 내 모든 파일 또는 대부분의 파일이 관련 있을 때 | 현재 작업과 무관한 컨텍스트가 많이 포함될 수 있음 |
규칙
/Generate Cursor Rules로 뽑아낼 수 있어. 프롬프트가 오간 긴 대화를 했다면, 나중에 재사용하고 싶은 유용한 지시나 일반 규칙이 꽤 있을 거야.
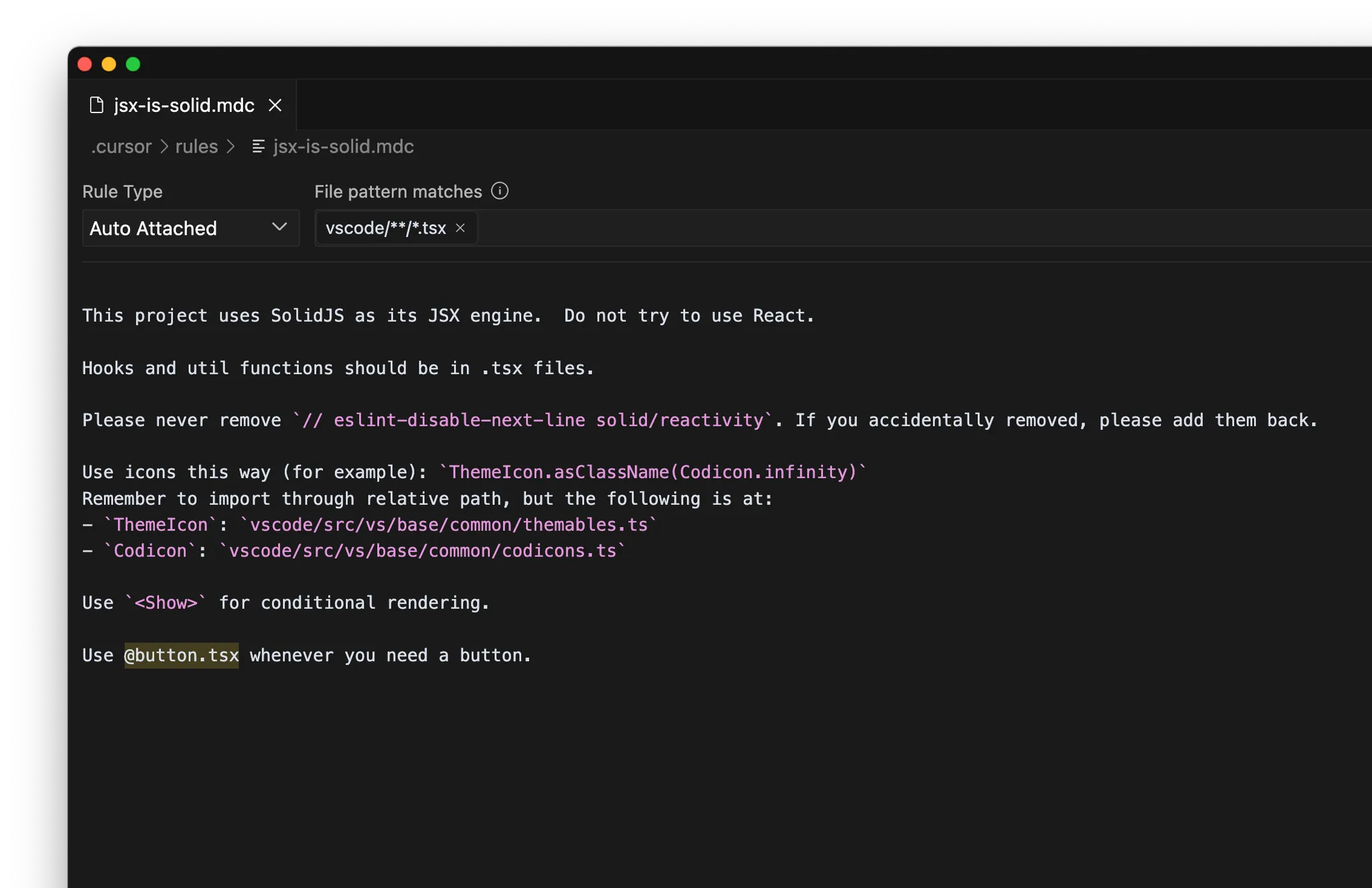
MCP
- 내부 문서: 예) Notion, Confluence, Google Docs
- 프로젝트 관리: 예) Linear, Jira
자체 컨텍스트 수집
- 코드의 관련 부분에 print(“debugging: …”) 구문을 추가하기
- 터미널을 사용해 코드나 테스트 실행하기
핵심 요점
- 컨텍스트는 효과적인 AI 코딩의 토대이며, 의도(무엇을 원하는지)와 상태(현재 무엇이 있는지)로 구성돼. 둘 다 제공하면 Cursor가 더 정확하게 예측해.
- 자동 컨텍스트 수집에만 맡기지 말고, @기호(@code, @file, @folder)를 써서 정밀한 컨텍스트로 Cursor를 정확히 안내해.
- 재사용 가능한 지식은 규칙으로 정리해 팀 전체가 쓰게 하고, 외부 시스템을 연결하려면 Model Context Protocol로 Cursor의 기능을 확장해.
- 컨텍스트가 부족하면 환각이나 비효율이 생기고, 관련 없는 컨텍스트가 너무 많으면 신호가 약해져. 최적의 결과를 위해 균형을 맞춰.