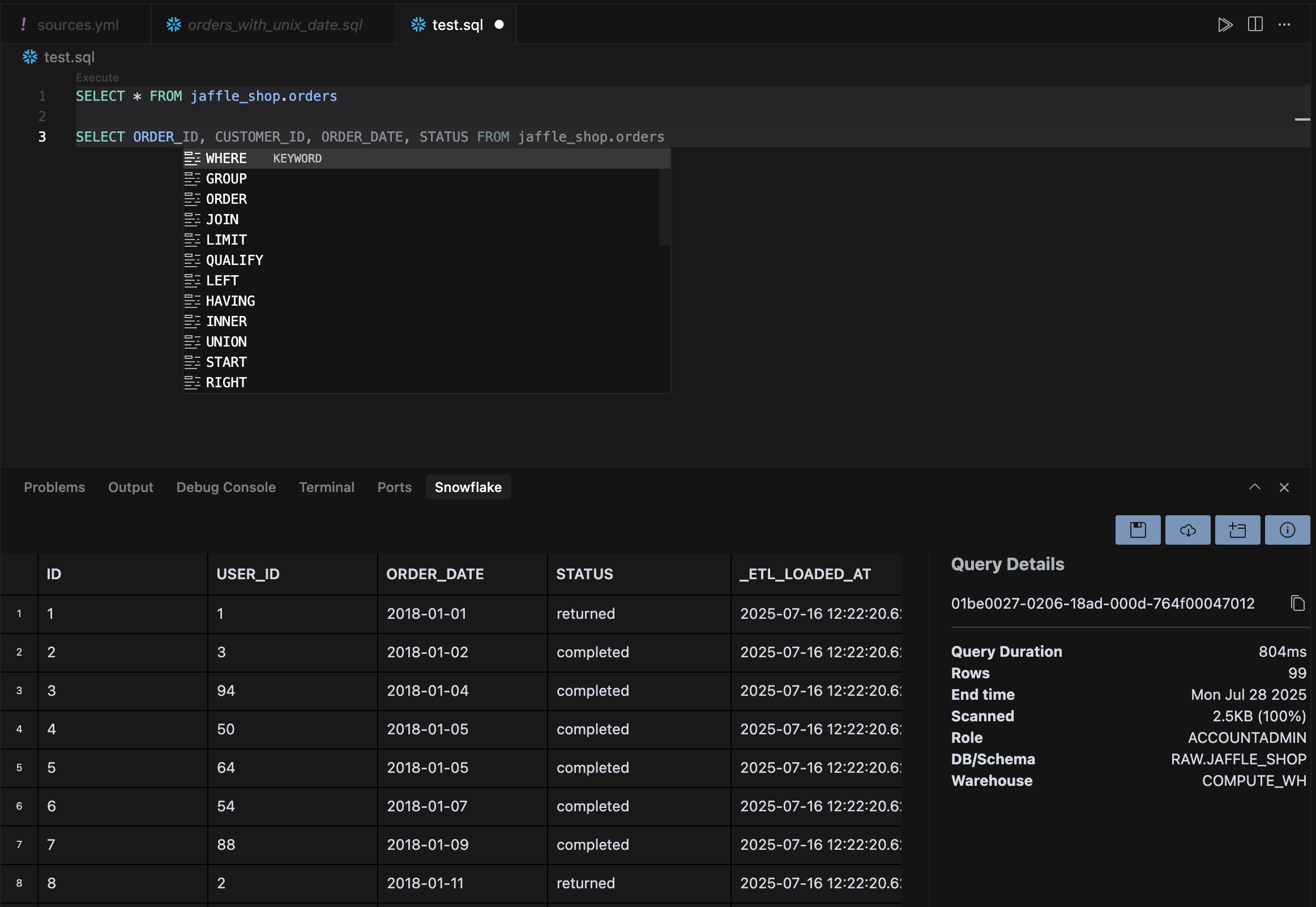
MCP 서버를 쓰면 에이전트가 데이터베이스에 직접 쿼리를 날릴 수 있어. 이를 통해 에이전트는 데이터베이스를 조회할지 결정하고, 적절한 쿼리를 작성하고, 명령을 실행하고, 결과를 분석하는 전 과정을 진행 중인 작업의 일부로 수행할 수 있어.예를 들어, 다음 MCP config를 Cursor에 추가해서 Postgres 데이터베이스를 너의 Cursor 인스턴스에 연결할 수 있어:
에디터에서 바로 쿼리를 실행하려면 데이터베이스별 확장 프로그램(PostgreSQL, BigQuery, SQLite, Snowflake)을 설치해. 이렇게 하면 도구 간 컨텍스트 전환을 없애고, 쿼리 최적화를 위한 AI 도움도 받을 수 있어.
복사
AI에게 묻기
-- Cursor는 인덱스, 윈도 함수, 쿼리 최적화에 대한 제안을 제공해SELECT user_id, event_type, COUNT(*) as event_count, RANK() OVER (PARTITION BY user_id ORDER BY COUNT(*) DESC) as frequency_rankFROM eventsWHERE created_at >= NOW() - INTERVAL '7 days'GROUP BY user_id, event_type;
느린 쿼리를 분석하고 성능 개선을 제안하거나, 쿼리 결과를 위한 시각화 코드를 생성하려면 Agents를 써봐. Cursor는 SQL 문맥을 이해하고 데이터 구조에 맞는 적절한 차트 유형을 추천해줄 수 있어.
Cursor의 AI 지원은 Matplotlib, Plotly, Seaborn 같은 데이터 시각화 라이브러리까지 커버해. 에이전트가 시각화 코드를 생성해줘서 데이터를 빠르고 쉽게 탐색할 수 있고, 재현 가능하고 공유하기 좋은 아티팩트도 만들어줘.
복사
AI에게 묻기
import plotly.express as pximport pandas as pd# AI가 데이터 열을 바탕으로 적합한 그래프 유형을 제안함df = pd.read_csv('sales_data.csv')fig = px.scatter(df, x='advertising_spend', y='revenue', color='region', size='customer_count', title='지역별 광고비와 매출'fig.show()
기존 Jupyter 노트북을 사용할 수 있어?
응, Cursor는 .ipynb 파일을 열어서 셀 단위 실행과 AI 코드 보완을 완전히 지원해.메모리에 안 들어가는 대규모 데이터셋은 어떻게 처리해?
Dask 같은 분산 컴퓨팅 라이브러리를 쓰거나, Remote-SSH로 더 큰 머신의 Spark 클러스터에 연결해.Cursor가 R이랑 SQL 파일도 지원해?
응, Cursor는 R 스크립트(.R)랑 SQL 파일(.sql)에 대해 AI 지원이랑 구문 하이라이팅을 제공해.개발 환경을 공유하는 권장 방법이 뭐야?.devcontainer 폴더를 버전 관리에 커밋해. 팀원이 프로젝트를 열면 환경을 자동으로 다시 빌드할 수 있어.데이터 처리 파이프라인은 어떻게 디버깅해?
Cursor의 통합 디버거로 Python 스크립트에 브레이크포인트를 걸어 디버깅하거나, Agent를 활용해 복잡한 데이터 변환을 단계별로 분석하고 설명받아.
개발 컨테이너는 팀원과 배포 환경 전반에서 런타임과 의존성을 일관되게 유지하는 데 도움을 줘. 환경 특이적 버그를 없애고 새 팀원의 온보딩 시간을 줄일 수 있어.개발 컨테이너를 쓰려면 저장소 루트에 .devcontainer 폴더를 만드는 것부터 시작해. 그다음 devcontainer.json, Dockerfile, requirements.txt 파일을 만들어.
# requirements.txtpandas==2.3.0numpy# 프로젝트에 필요한 다른 의존성을 추가해줘
Cursor가 devcontainer를 자동으로 감지하고 컨테이너에서 프로젝트를 다시 열도록 안내해줘. 아니면 Command Palette(Ctrl+Shift+P)에서 Reopen in Container를 검색해 수동으로 컨테이너에서 다시 열어도 돼.Development container는 다음과 같은 이점을 제공해: