コンテキストって何?
- インテントコンテキスト は、ユーザーがモデルに何をしてほしいかを定義する。たとえば、システムプロンプトはモデルにどう振る舞ってほしいかを示す高レベルな指示として機能する。Cursorで行われる多くの「プロンプト作成」はインテントコンテキストにあたる。「そのボタンを青から緑に変えて」は明示的なインテントの例で、これは指示的。
- ステートコンテキスト は、現在の状態を記述する。エラーメッセージ、コンソールログ、画像、コード片をCursorに提供するのは、状態に関するコンテキストの例。これは記述的で、指示的ではない。
Cursor でコンテキストを提供する
- パターンがないのにパターンマッチしようとして幻覚が生じ、想定外の結果になる。これはコンテキストが不足しているとき、
claude-3.5-sonnetのようなモデルで頻繁に起こりうる。 - Agent がコードベース検索、ファイルの読み取り、ツール呼び出しによって自力でコンテキスト収集を試みる。強力な思考系モデル(
claude-3.7-sonnetなど)はこの戦略でかなり進められるが、最初に適切な初期コンテキストを与えるかどうかで以後の軌道が決まる。
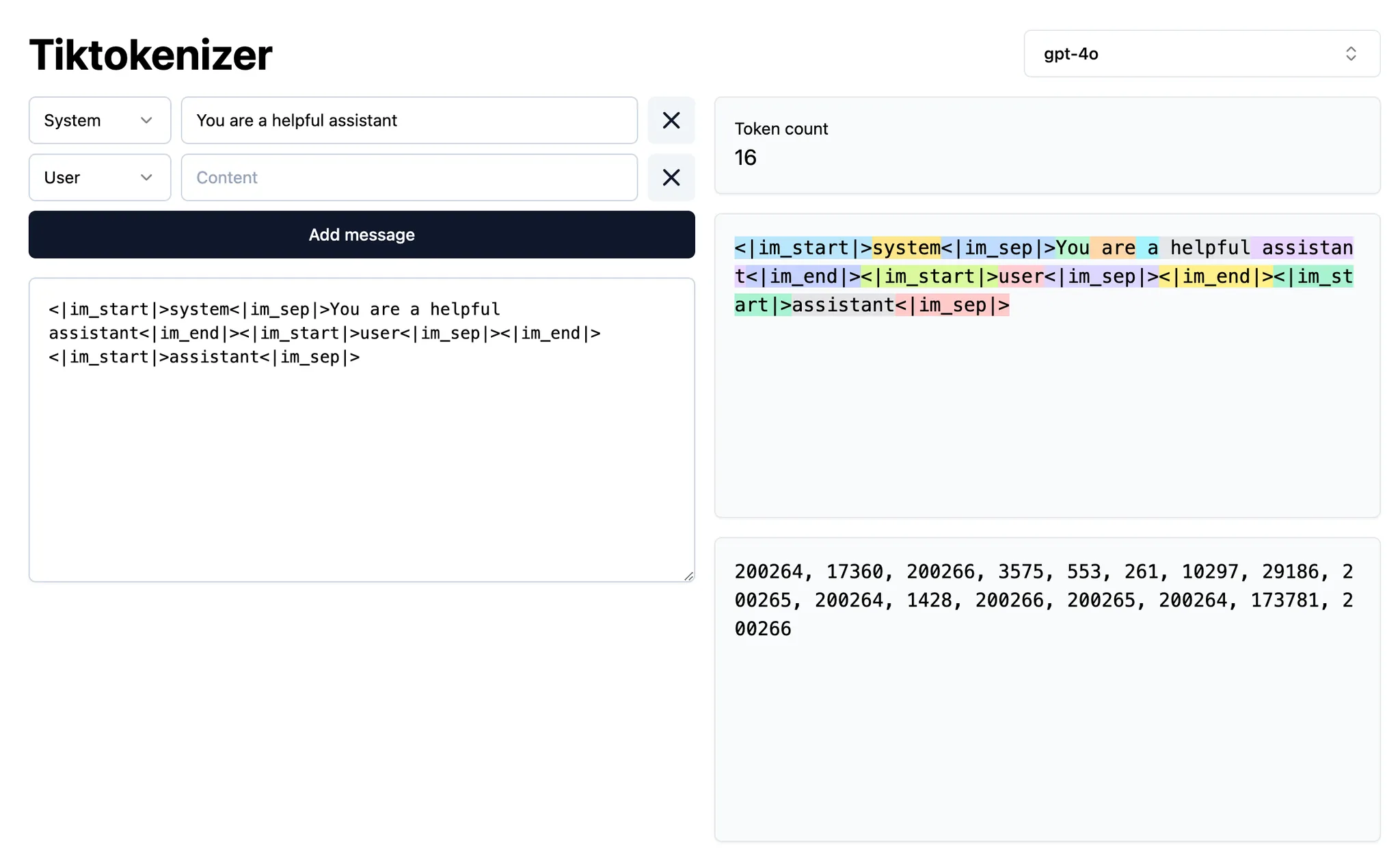
@-symbol
| Symbol | Example | Use case | Drawback |
|---|---|---|---|
@code | @LRUCachedFunction | 生成する出力に関係する関数・定数・シンボルがどれか分かっているとき | コードベースについて幅広い知識が必要 |
@file | cache.ts | 読む/編集すべきファイルは分かるが、ファイル内の正確な位置は不明 | ファイルサイズ次第で、タスクに無関係なコンテキストが多く含まれる可能性がある |
@folder | utils/ | フォルダ内のすべて/大半のファイルが関連しているとき | タスクに無関係なコンテキストが多く含まれる可能性がある |
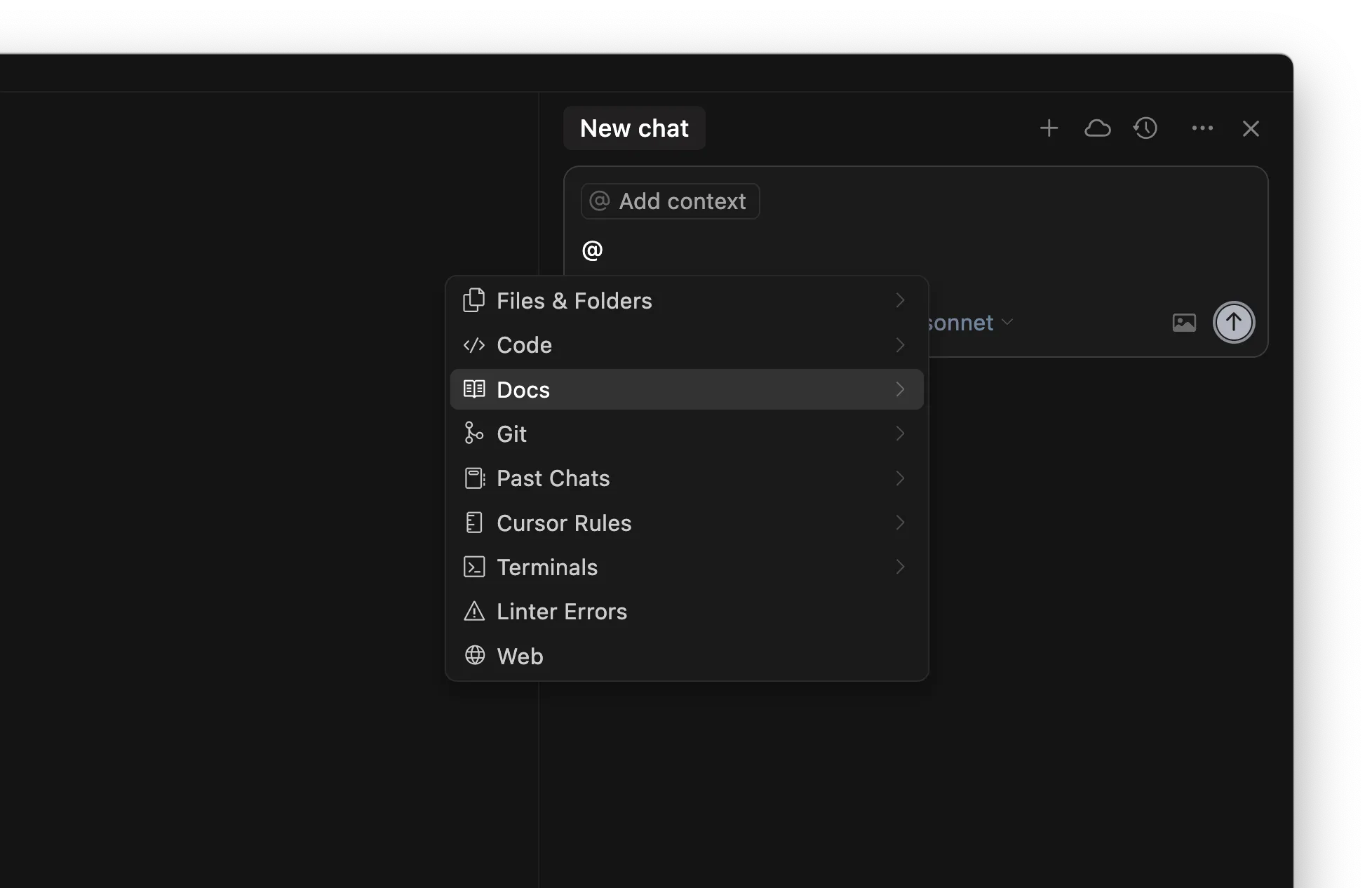
ルール
/Generate Cursor Rules を使って生成することもできる。長いやり取りでプロンプトを多用していたなら、あとで再利用したくなる有用な指示や一般的なルールが見つかるはず。
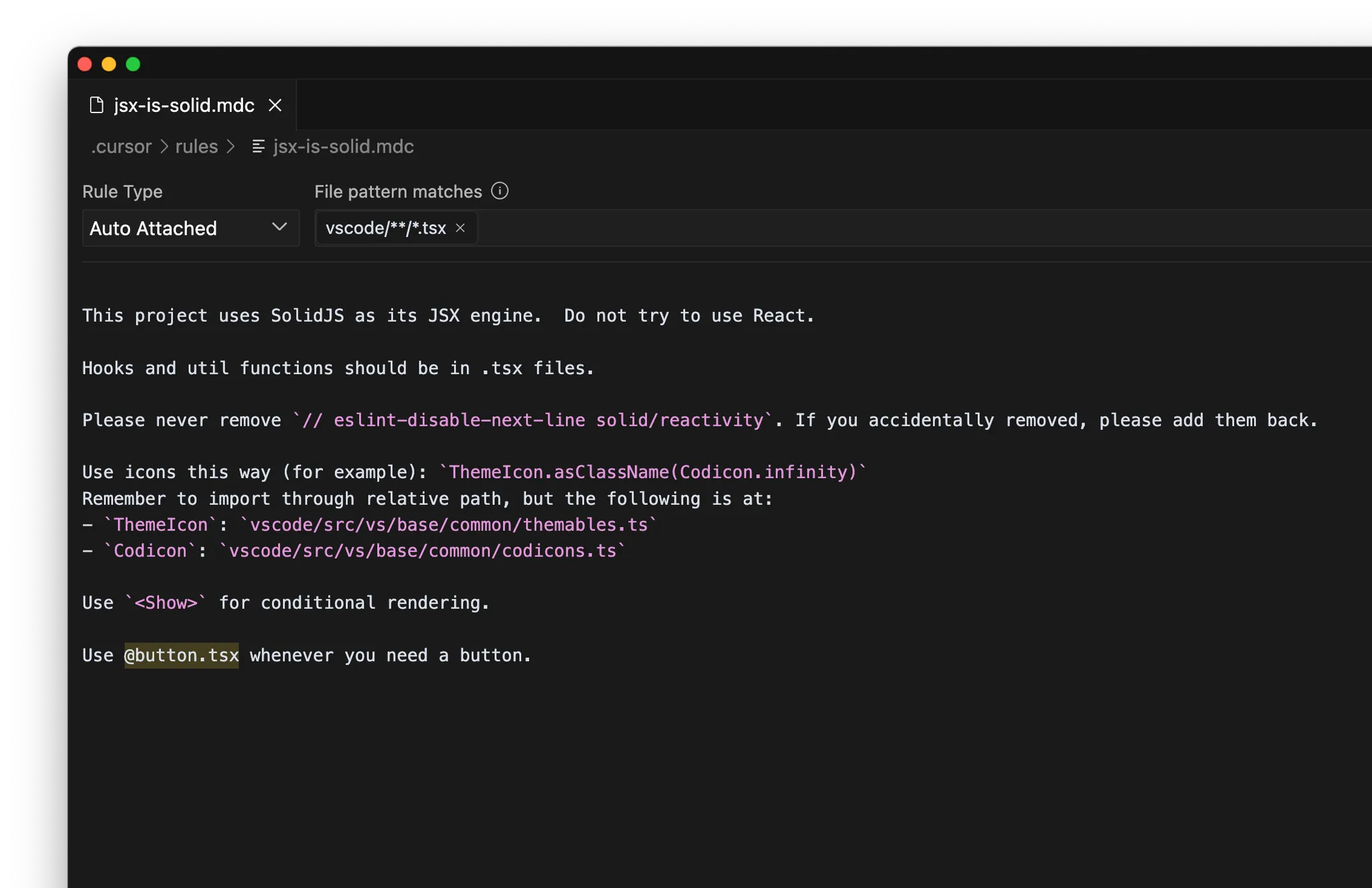
MCP
- 内部ドキュメント: 例: Notion、Confluence、Google Docs
- プロジェクト管理: 例: Linear、Jira
自己収集コンテキスト
- コードの適切な箇所に print(“debugging: …”) ステートメントを追加する
- ターミナルでコードやテストを実行する
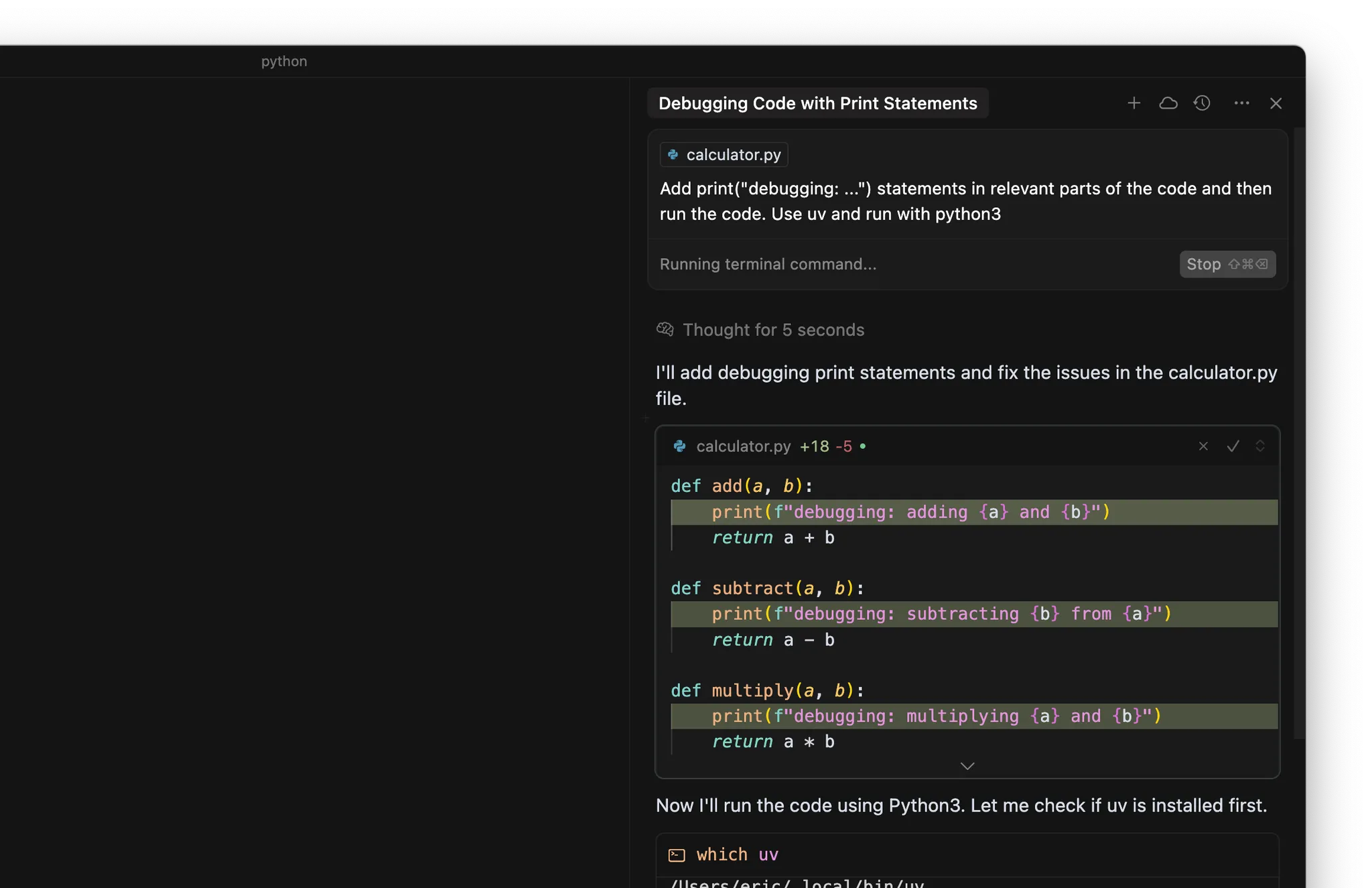
まとめ
- コンテキストは効果的なAIコーディングの基盤で、意図(何をしたいか)と状態(何があるか)で構成される。両方を提供すると、Cursorがより正確に予測できる。
- 自動コンテキスト収集だけに頼らず、@記号(@code、@file、@folder)を使ったピンポイントなコンテキスト指定で、Cursorを的確に誘導する。
- 繰り返し使う知識はルールとして体系化してチームで再利用し、Model Context Protocolで外部システムと接続してCursorの機能を拡張する。
- コンテキストが不十分だとハルシネーションや非効率を招き、無関係なコンテキストが多すぎるとシグナルが希薄化する。最適な結果のために適切なバランスを取る。