Lerne, wie du Cursor für Data-Science-Workflows einrichtest – inklusive Python, R und SQL – mit Notebooks, Remote-Umgebungen und KI-gestützter Analyse
Cursor bietet integrierte Tools für Data-Science-Entwicklung: reproduzierbare Umgebungen, Notebook-Support und KI-gestützte Code-Hilfe. Dieser Guide behandelt essenzielle Setup-Patterns für Python-, R- und SQL-Workflows.
Für vollständige Notebook-Unterstützung lade die Jupyter-Erweiterung (ID: ms-toolsai.jupyter) von ms-toolsai herunter.
Cursor unterstützt sowohl .ipynb- als auch .py-Dateien mit integrierter Zellausführung. Tab, Inline Edit und Agents
funktionieren in Notebooks genauso wie in anderen Code-Dateien.Wichtige Funktionen:
Inline-Zellausführung führt Code direkt in der Editoroberfläche aus
Tab, Inline Edit und Agent verstehen Data-Science-Bibliotheken, einschließlich pandas, NumPy, scikit-learn und SQL-Magic-Befehlen
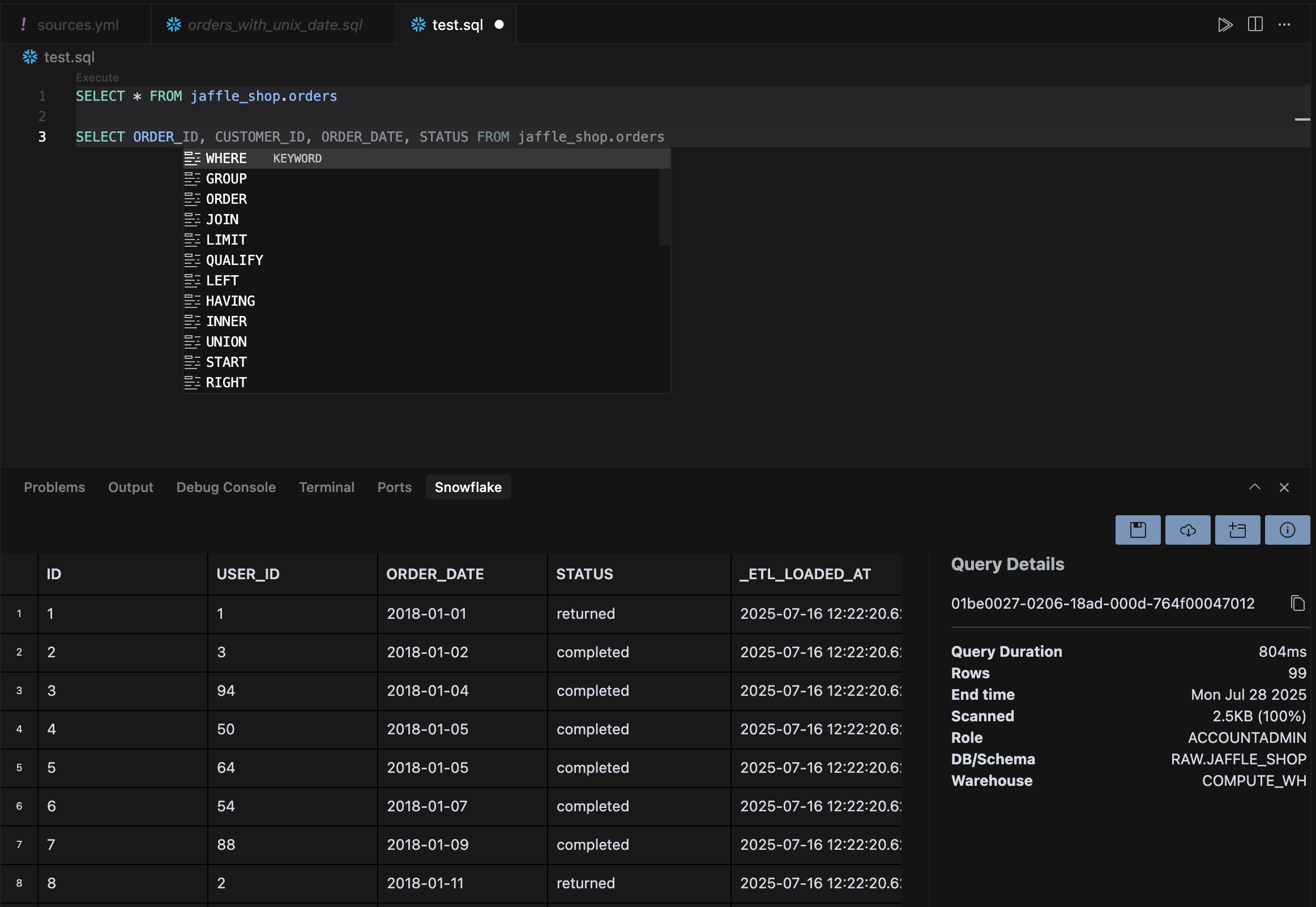
MCP-Server erlauben deinem Agent, Abfragen direkt gegen deine Datenbank auszuführen. So kann dein Agent entscheiden, deine Datenbank zu queryen, die passende Abfrage zu schreiben, den Befehl auszuführen und die Ergebnisse zu analysieren – alles als Teil einer laufenden Aufgabe.Zum Beispiel kannst du eine Postgres-Datenbank mit deiner Cursor-Instanz verbinden, indem du die folgende MCP-Konfiguration zu Cursor hinzufügst:
Installiere datenbankspezifische Extensions (PostgreSQL, BigQuery, SQLite, Snowflake), um Queries direkt im Editor auszuführen. Das spart Kontextwechsel zwischen Tools und ermöglicht KI-Unterstützung bei der Query-Optimierung.
Kopieren
KI fragen
-- Cursor schlägt Indizes, Window-Funktionen und Query-Optimierungen vorSELECT user_id, event_type, COUNT(*) as event_count, RANK() OVER (PARTITION BY user_id ORDER BY COUNT(*) DESC) as frequency_rankFROM eventsWHERE created_at >= NOW() - INTERVAL '7 days'GROUP BY user_id, event_type;
Nutze Agents, um langsame Abfragen zu analysieren, Leistungsverbesserungen vorzuschlagen oder Visualisierungscode für Abfrageergebnisse zu erzeugen. Cursor versteht den SQL-Kontext und kann basierend auf deiner Datenstruktur passende Diagrammtypen empfehlen.
Cursors KI-Unterstützung umfasst Datenvisualisierungsbibliotheken wie Matplotlib, Plotly und Seaborn. Der Agent kann Code für Datenvisualisierung generieren, sodass du Daten schnell und einfach erkunden kannst – und dabei ein reproduzierbares, leicht teilbares Artefakt entsteht.
Kopieren
KI fragen
import plotly.express as pximport pandas as pd# Die KI schlägt auf Basis der Datenspalten passende Diagrammtypen vordf = pd.read_csv('sales_data.csv')fig = px.scatter(df, x='advertising_spend', y='revenue', color='region', size='customer_count', title='Umsatz vs. Werbeausgaben nach Region')fig.show()
Kann ich vorhandene Jupyter-Notebooks verwenden?
Ja, Cursor öffnet .ipynb-Dateien mit vollständiger Zellausführung und KI-gestützter Autovervollständigung.Wie gehe ich mit großen Datensätzen um, die nicht in den Speicher passen?
Verwende verteilte Computing-Bibliotheken wie Dask oder verbinde dich per Remote-SSH mit größeren Maschinen und Spark-Clustern.Unterstützt Cursor R- und SQL-Dateien?
Ja, Cursor bietet KI-Unterstützung und Syntaxhervorhebung für R-Skripte (.R) und SQL-Dateien (.sql).Was ist der empfohlene Weg, Entwicklungsumgebungen zu teilen?
Committe den Ordner .devcontainer in die Versionsverwaltung. Teammitglieder können die Umgebung beim Öffnen des Projekts automatisch neu aufsetzen.Wie debugge ich Datenverarbeitungspipelines?
Verwende den integrierten Debugger von Cursor mit Breakpoints in Python-Skripten, oder nutze Agent, um komplexe Datentransformationen Schritt für Schritt zu analysieren und zu erklären.
Entwicklungscontainer helfen dir, einheitliche Runtimes und Abhängigkeiten über Teammitglieder und Deploy-Umgebungen hinweg sicherzustellen. Sie können umgebungsspezifische Bugs eliminieren und die Einarbeitungszeit für neue Teammitglieder verkürzen.Um einen Entwicklungscontainer zu verwenden, leg zuerst einen Ordner .devcontainer im Root deines Repos an. Erstelle anschließend eine devcontainer.json, ein Dockerfile und eine requirements.txt.
# requirements.txtpandas==2.3.0numpy# füge weitere Abhängigkeiten hinzu, die du für dein Projekt brauchst
Cursor erkennt den Dev Container automatisch und fordert dich auf, dein Projekt in einem Container neu zu öffnen. Alternativ kannst du die Command Palette (Ctrl+Shift+P) nutzen und nach Reopen in Container suchen, um das Projekt manuell in einem Container neu zu öffnen.Entwicklungscontainer bieten mehrere Vorteile:
Isolierte Abhängigkeiten verhindern Konflikte zwischen Projekten
Reprodizierbare Builds sorgen für konsistentes Verhalten in Entwicklungs- und Produktionsumgebungen
Vereinfachtes Onboarding ermöglicht neuen Teammitgliedern, ohne manuelle Einrichtung sofort loszulegen
Wenn deine Arbeit zusätzliche Rechenressourcen, GPUs oder Zugriff auf private Datensätze erfordert, verbinde dich mit Remote-Maschinen, während du deine lokale Entwicklungsumgebung beibehältst.
Bereitstelle eine Cloud-Instanz oder greife auf einen On-Premises-Server mit den benötigten Ressourcen zu
Klone dein Repository auf die Remote-Maschine, einschließlich der .devcontainer-Konfiguration
Verbinde dich über Cursor: Ctrl+Shift+P → „Remote-SSH: Connect to Host“
Dieser Ansatz erhält ein konsistentes Tooling, während die Rechenressourcen bei Bedarf skaliert werden. Die gleiche Entwicklungscontainer-Konfiguration funktioniert sowohl in lokalen als auch in Remote-Umgebungen.