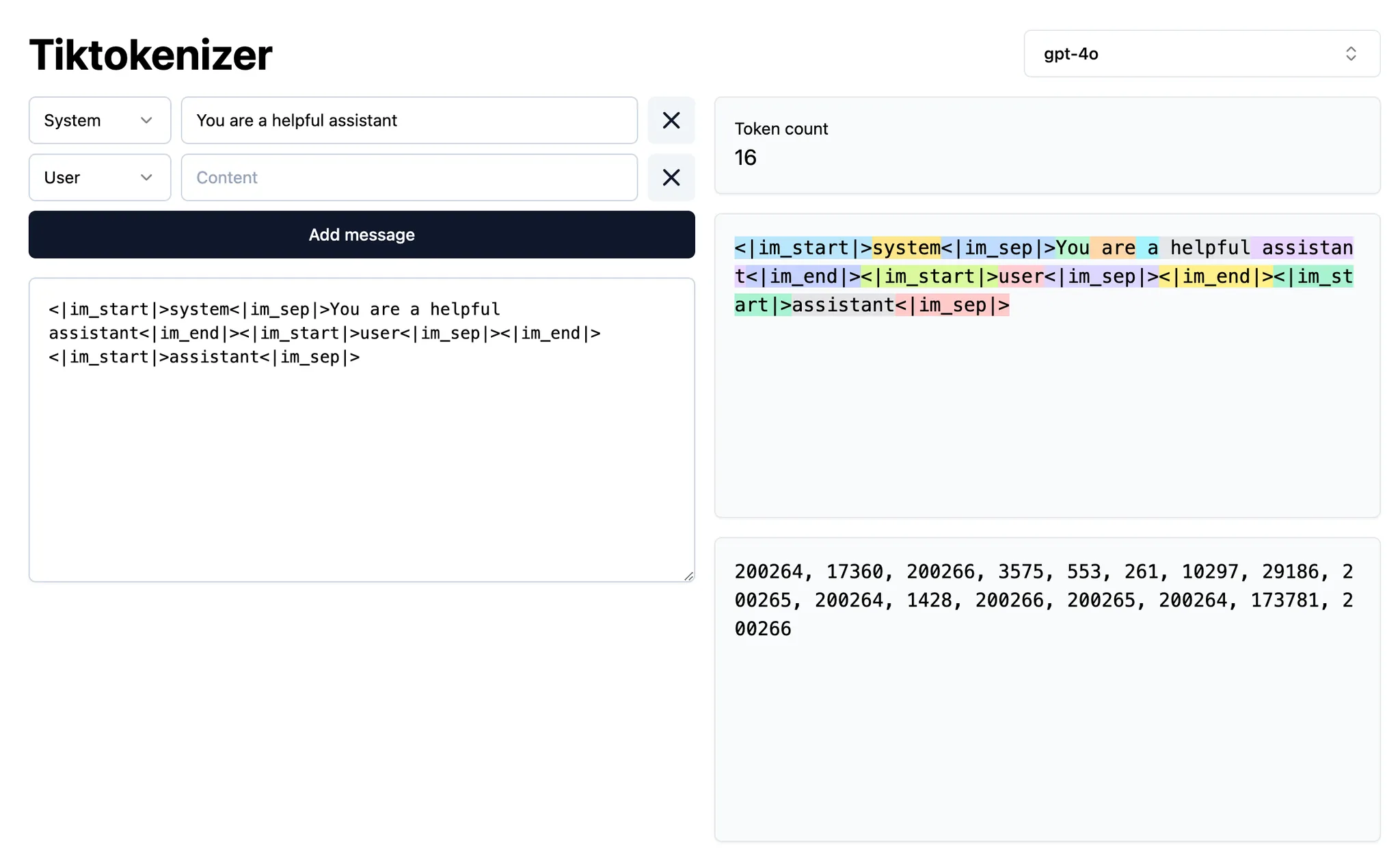
Was ist Kontext?
- Intent-Kontext definiert, was der User vom Modell will. Zum Beispiel dienen Systemprompts normalerweise als High-Level-Anweisungen dafür, wie sich das Modell verhalten soll. Das meiste „Prompting“ in Cursor ist Intent-Kontext. „Mach den Button von blau zu grün“ ist ein Beispiel für geäußerte Intention; das ist präskriptiv.
- State-Kontext beschreibt den aktuellen Zustand. Cursor mit Fehlermeldungen, Konsolen-Logs, Bildern und Codeausschnitten zu versorgen, sind Beispiele für zustandsbezogenen Kontext. Er ist deskriptiv, nicht präskriptiv.
Kontext in Cursor bereitstellen
- Halluzinationen, bei denen das Modell versucht, Muster zu erkennen (obwohl es keine gibt), was zu unerwarteten Ergebnissen führt. Das kann bei Modellen wie
claude-3.5-sonnethäufig passieren, wenn sie nicht genug Kontext bekommen. - Der Agent versucht, sich den Kontext selbst zu beschaffen, indem er die Codebase durchsucht, Dateien liest und Tools aufruft. Ein starkes Thinking-Modell (wie
claude-3.7-sonnet) kann mit dieser Strategie ziemlich weit kommen, und der richtige initiale Kontext setzt die Richtung.
@-symbol
| Symbol | Example | Use case | Drawback |
|---|---|---|---|
@code | @LRUCachedFunction | Du weißt, welche Funktion, Konstante oder welches Symbol für den Output relevant ist | Erfordert viel Wissen über die Codebasis |
@file | cache.ts | Du weißt, welche Datei gelesen oder bearbeitet werden soll, aber nicht genau, wo darin | Könnte je nach Dateigröße viel irrelevanten Kontext für die aktuelle Aufgabe enthalten |
@folder | utils/ | Alles oder der Großteil der Dateien in einem Ordner ist relevant | Könnte viel irrelevanten Kontext für die aktuelle Aufgabe enthalten |
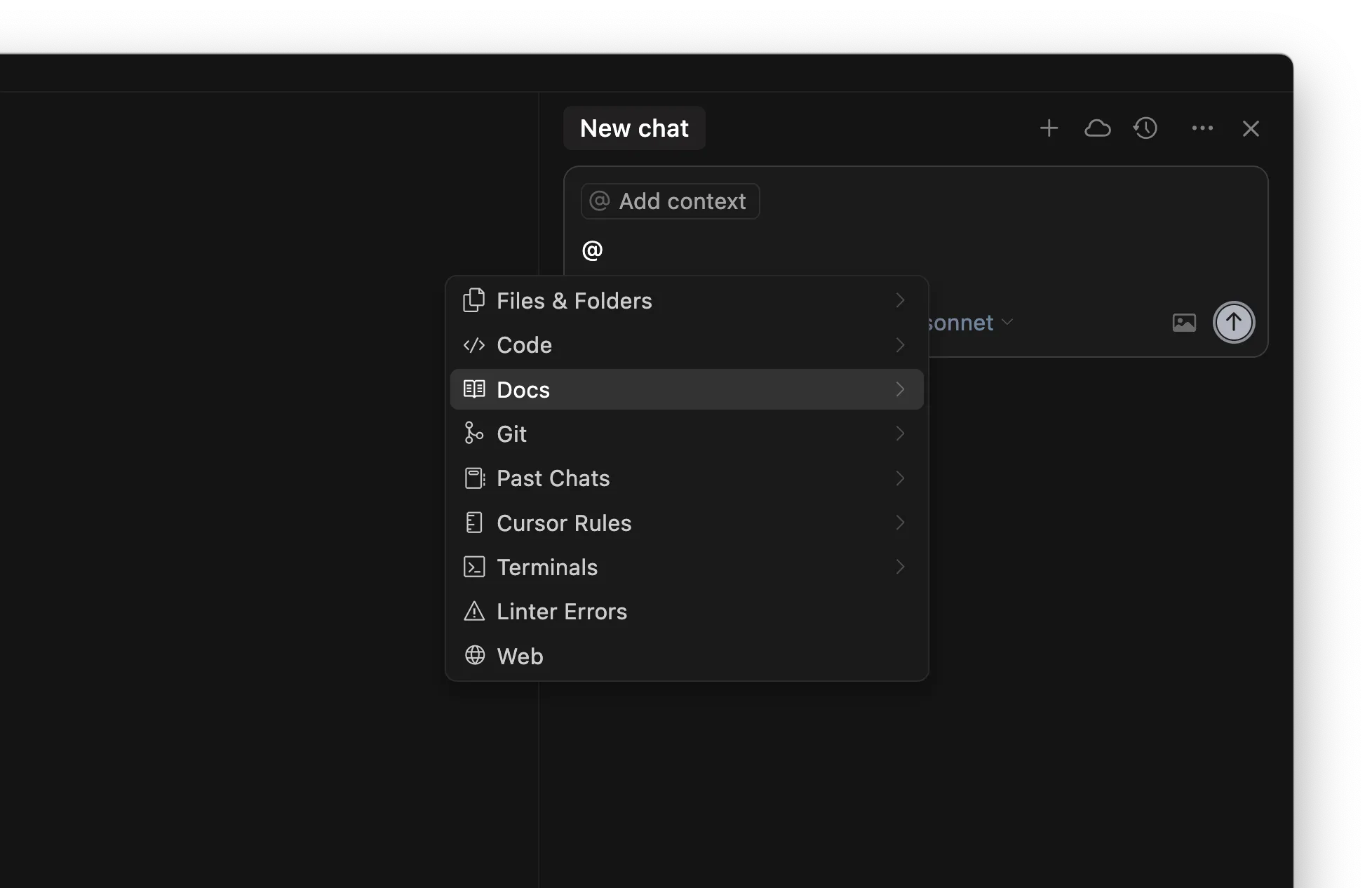
Regeln
/Generate Cursor Rules erstellen. Wenn du eine längere Unterhaltung mit viel Prompting geführt hast, gibt es wahrscheinlich nützliche Vorgaben oder allgemeine Regeln, die du später wiederverwenden willst.
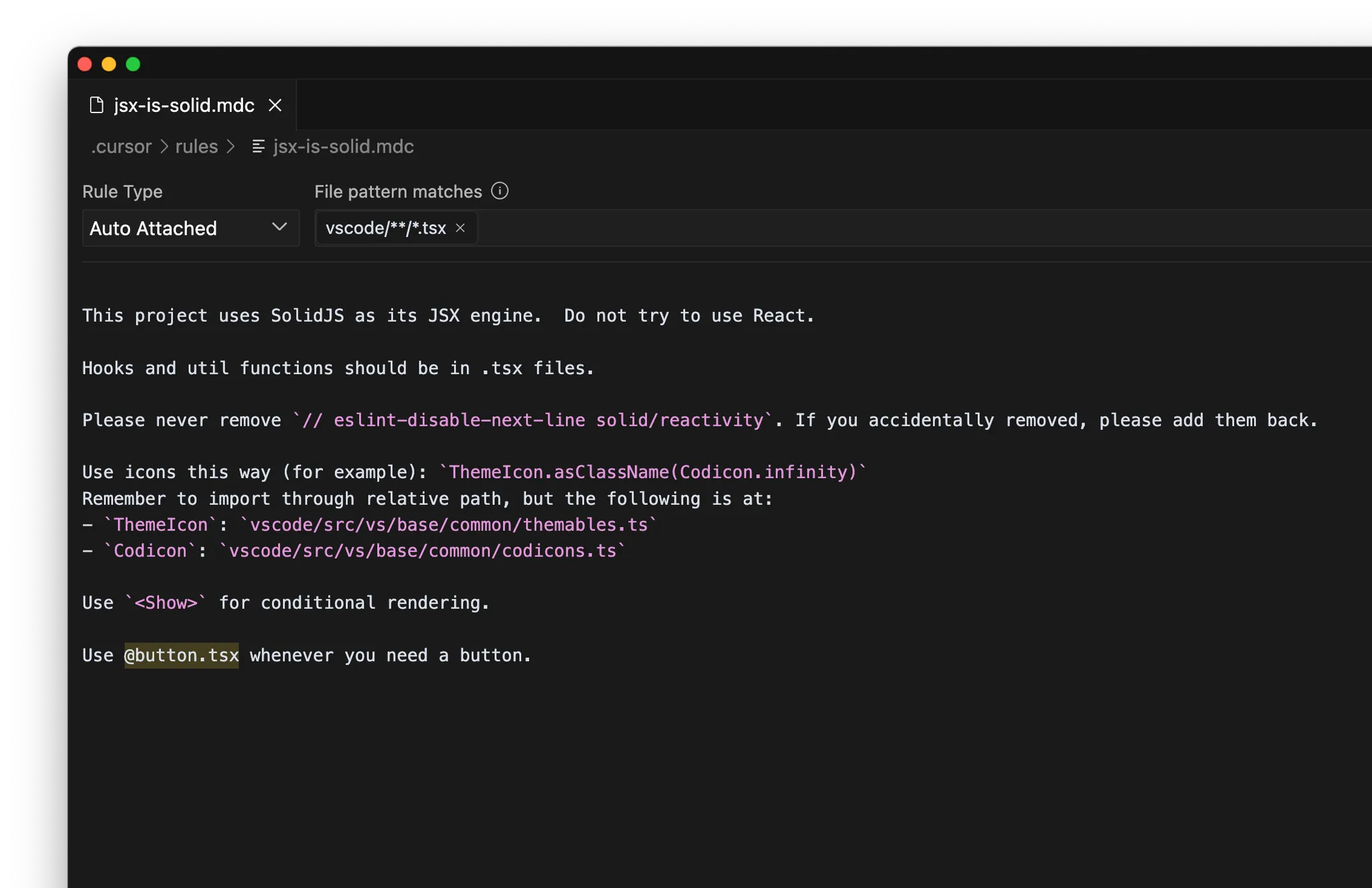
MCP
- Interne Dokumentation: z. B. Notion, Confluence, Google Docs
- Projektmanagement: z. B. Linear, Jira
Selbstständig Kontext sammeln
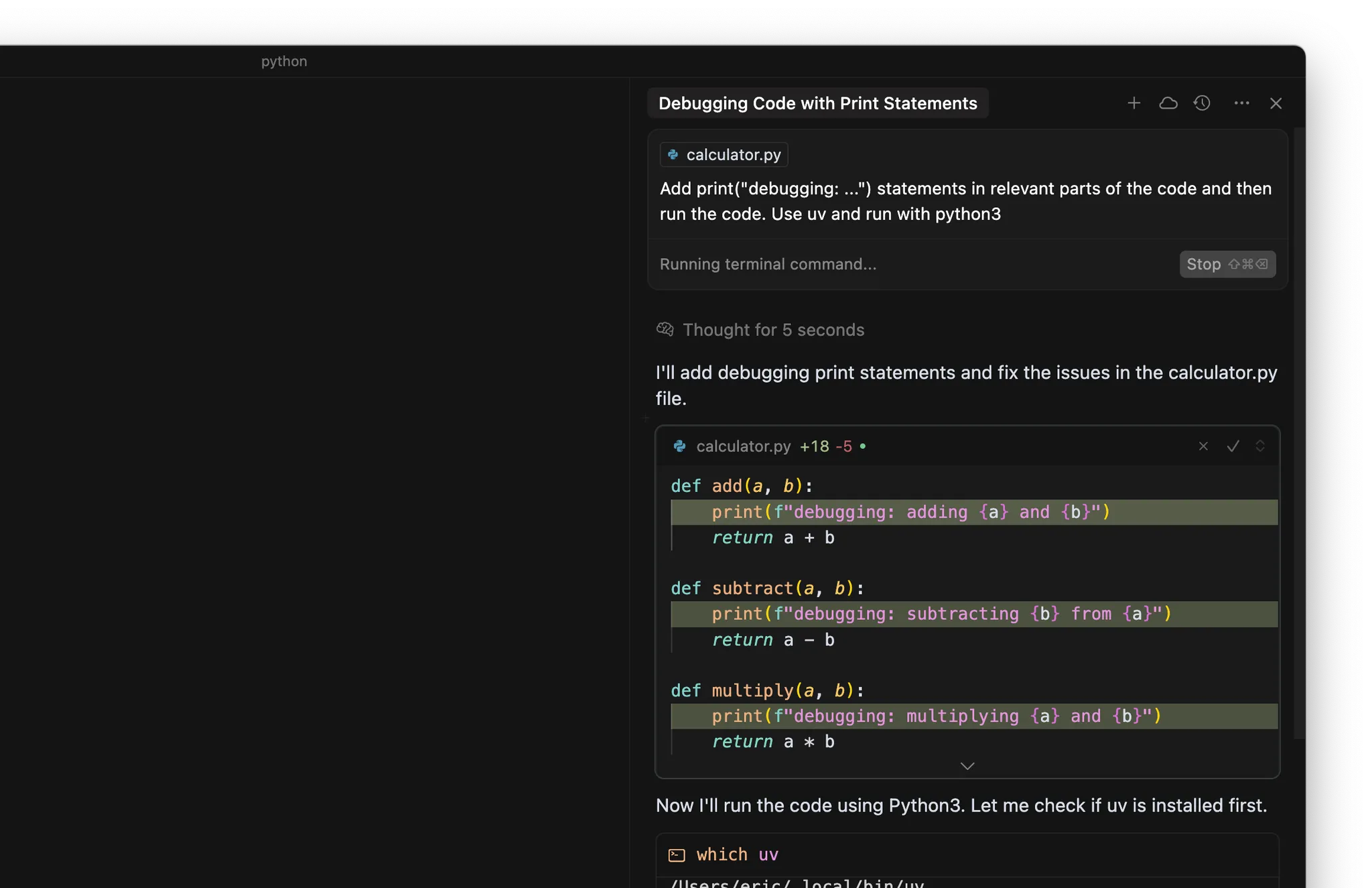
- Füge print(“debugging: …”)-Ausgaben an relevanten Stellen im Code ein
- Führe den Code oder die Tests im Terminal aus
Wichtigste Erkenntnisse
- Kontext ist die Grundlage effektiven AI-Codings und besteht aus Absicht (was du willst) und Zustand (was bereits existiert). Wenn du beides lieferst, kann Cursor präzise Vorhersagen treffen.
- Nutze gezielten Kontext mit @-Symbolen (@code, @file, @folder), um Cursor präzise zu steuern, statt dich nur auf automatische Kontextsammlung zu verlassen.
- Halte wiederverwendbares Wissen in Regeln fest, um es teamweit zu teilen, und erweitere Cursors Fähigkeiten mit dem Model Context Protocol, um externe Systeme anzubinden.
- Zu wenig Kontext führt zu Halluzinationen oder Ineffizienz, während zu viel irrelevanter Kontext das Signal verwässert. Finde das richtige Gleichgewicht für optimale Ergebnisse.