MCP-Server lassen dich eigene Datenquellen anbinden und in Cursor verfügbar machen. Das ist besonders nützlich, wenn du Kontext aus Quellen wie Browsern, Datenbanken oder Fehler- und System-Logs brauchst. Das Einrichten eines MCP-Servers ist unkompliziert und mit Cursor schnell erledigt.In diesem Guide zeigen wir, wie du einen MCP-Server für Postgres baust. Unser Ziel ist, Cursor zu ermöglichen, SQL-Abfragen direkt gegen eine Postgres-Datenbank auszuführen und Tabellenschemata strukturiert bereitzustellen.
Dieses Tutorial soll dir die Grundlagen zum Erstellen von MCP-Servern vermitteln.
Ein MCP-Server ist ein Prozess, der mit Cursor kommuniziert und Zugriff auf externe Daten oder Aktionen bereitstellt. Er kann auf mehrere Arten implementiert werden, aber hier nutzen wir die einfachste Methode: einen Server, der lokal auf deinem Computer über stdio (Standard-Ein-/Ausgabeströme) läuft. Das vermeidet komplizierte Sicherheitsüberlegungen und lässt uns auf die MCP-Logik selbst fokussieren.Einer der häufigsten Anwendungsfälle für MCP ist der Datenbankzugriff. Beim Erstellen von Dashboards, dem Ausführen von Analysen oder dem Erstellen von Migrationen ist es oft notwendig, eine Datenbank zu abzufragen und zu inspizieren. Unser Postgres-MCP-Server wird zwei Kernfunktionen unterstützen: das Ausführen beliebiger Abfragen und das Auflisten von Tabellenschemata.Obwohl beide Aufgaben auch mit reinem SQL erledigt werden könnten, bietet MCP Funktionen, die sie mächtiger und allgemein nützlicher machen. Tools bieten eine Möglichkeit, Aktionen wie das Ausführen von Abfragen bereitzustellen, während Ressourcen es ermöglichen, standardisierten Kontext wie Schemainformationen zu teilen. Später in diesem Guide schauen wir uns auch Prompts an, die fortgeschrittenere Workflows ermöglichen.Unter der Haube verlassen wir uns auf das npm-Paket postgres, um SQL-Anweisungen gegen die Datenbank auszuführen. Das MCP-SDK dient als Wrapper um diese Aufrufe und ermöglicht es uns, Postgres-Funktionalität nahtlos in Cursor zu integrieren.
Der erste Schritt beim Erstellen des Servers ist, ein neues Projekt aufzusetzen. Wir fangen damit an, einen neuen Ordner zu erstellen und ein Bun-Projekt zu initialisieren.
Kopieren
KI fragen
> mkdir postgres-mcp-server> Bun init
Von hier aus wählen wir das Blank-Projekt. Sobald unser Boilerplate eingerichtet ist, müssen wir die benötigten Abhängigkeiten installieren. zod wird benötigt, um Schemas für I/O im MCP-SDK zu definieren
Kopieren
KI fragen
bun add postgres @modelcontextprotocol/sdk zod
Von hier aus gehen wir zu den Repos der jeweiligen Libraries und holen uns den Link zu den Rohinhalten der jeweiligen README-Dateien. Die nutzen wir als Kontext, wenn wir den Server bauen.
Jetzt definieren wir, wie sich der Server verhalten soll. Dafür erstellen wir eine spec.md und schreiben die übergeordneten Ziele auf.
Kopieren
KI fragen
# Spezifikation- Definieren von DATABASE_URL über MCP-Umgebungskonfiguration erlauben- Postgres-Daten über ein Tool abfragen - Standardmäßig schreibgeschützt - Schreiboperationen erlauben, indem ENV `DANGEROUSLY_ALLOW_WRITE_OPS=true|1` gesetzt wird- Auf Tabellen als `resources` zugreifen- Zod für Schema-Definitionen verwenden
Wie du siehst, ist das eine ziemlich schlanke Spezifikation. Fühl dich frei, bei Bedarf weitere Details hinzuzufügen. Zusammen mit den README-Links erstellen wir den finalen Prompt.
Kopieren
KI fragen
Lies das Folgende und halte dich an @spec.md, um zu verstehen, was wir wollen. Alle erforderlichen Abhängigkeiten sind installiert- @https://raw.githubusercontent.com/modelcontextprotocol/typescript-sdk/refs/heads/main/README.md- @https://raw.githubusercontent.com/porsager/postgres/refs/heads/master/README.md
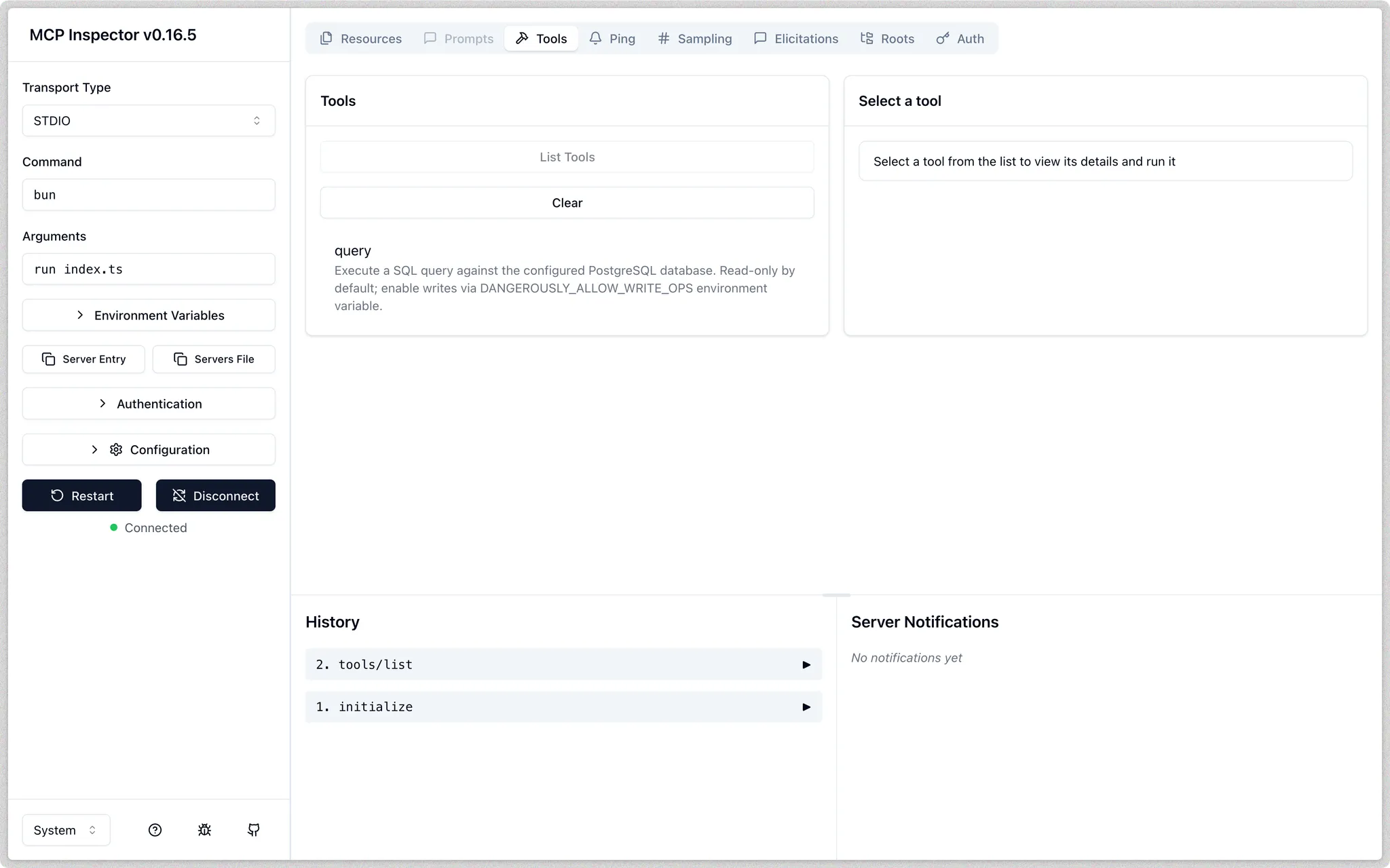
Mit diesen drei Komponenten (der Spezifikation, der MCP-SDK-Dokumentation und der Postgres-Bibliotheksdokumentation) können wir Cursor nutzen, um die Serverimplementierung zu scaffolden. Cursor hilft uns, die Bausteine zusammenzuführen und den Code zu generieren, der das MCP-SDK mit Postgres verbindet.Nach einigem Hin und Her beim Prompting haben wir jetzt eine erste Version des MCP-Servers am Start. Um sie auszuprobieren, können wir den MCP Inspector verwenden
Kopieren
KI fragen
npx @modelcontextprotocol/inspector bun run index.ts
Sobald die erste Implementierung steht, können wir sie mit dem MCP Inspector testen. Der Inspector zeigt, was der Server bereitstellt, und hilft zu prüfen, ob Tools und Ressourcen wie erwartet funktionieren. Wir sollten sicherstellen, dass Abfragen ausgeführt werden können und Schema-Informationen korrekt zurückgegeben werden.Wenn alles passt, können wir den Server mit Cursor verbinden und ihn in einer realen Umgebung testen. Ab diesem Zeitpunkt kann Cursor den Postgres-MCP-Server wie eine integrierte Funktion nutzen, sodass wir die Datenbank direkt abfragen und inspizieren können.
Den MCP-Server lokal über stdio auszuführen, ist ein super Einstieg, aber Teams brauchen oft gemeinsamen Zugriff auf dieselbe Datenbank über ihren MCP-Server. In solchen Fällen ist es nötig, den MCP-Server als zentralisierten HTTP-Dienst zu deployen.Ein bereitgestellter MCP-Server bietet mehrere Vorteile gegenüber einzelnen stdio-Instanzen:
Gemeinsamer Datenbankzugriff: Mehrere Teammitglieder können über Cursor dieselbe Datenbankinstanz abfragen
Zentralisierte Konfiguration: Schema-Updates und Berechtigungsänderungen werden an einem Ort verwaltet
Erhöhte Sicherheit: Saubere Authentifizierung, Rate-Limiting und Zugriffskontrollen können implementiert werden
Observability: Nutzungsmuster und Performance-Metriken können teamweit überwacht werden
Dafür würdest du die Transportmethode von stdio auf HTTP umstellen.Wir decken nicht das komplette Setup ab, aber hier ist ein guter Start-Prompt, den du Cursor geben kannst
Kopieren
KI fragen
Auf Basis des bestehenden MCP-Servers eine neue Datei erstellen, die das HTTP-Protokoll implementiert.Gemeinsame Logik nach mcp-core auslagern und jede Transport-Implementierung eindeutig benennen (mcp-server-stdio, mcp-server-http)@https://raw.githubusercontent.com/modelcontextprotocol/typescript-sdk/refs/heads/main/README.md
Die finalen Ergebnisse findest du hier: pg-mcp-server